Where do your text strings come from?
File : com.apple.screencapture.plist
Write the file :
Shell1.Execute ("defaults write com.apple.screencapture name " + TextFieldName.Text)
Read the file :
Shell1.Execute (“defaults read com.apple.screencapture name”)
French accents are processed in unicode codes (double slash+U+ unicode) in the name key (name of the file created).
I want to be able to read the string in clear and write it with these unicode codes.
We already had a discussion in the French channel, got nowhere. Apparently Denis does not want to explain what he is doing, and how he gets to that data. If he posted his code, that would be a great help to understand what he is after.
It’s done!
Now I get. He’s reading it and getting the unicode C escaped from the “defaults” app and want it re-encoded to UTF-8 to handle it in Xojo.
You need to write your “recomposer”. Something that reads your string, find the escapes “\UHHHH” and substitute them by the proper &uHHHH in Xojo (I mean, the proper codepoint).
1 Like
This can help
// EscapedUnicodeToUTF8("d\U2019e\U0301cran") -> "d’écran"
Private Function EscapedUnicodeToUTF8(escapedString As String) As String
Var UtfString As String = escapedString
Var re As new RegEx
Var match As RegExMatch
re.SearchPattern = "\\[Uu][0-9a-fA-F]{4,4}"
match = re.Search(UtfString)
Do until match = Nil
Var found, code As String
found = match.SubExpressionString(0)
code = Text.FromUnicodeCodepoint(Integer.FromHex(found.Middle(2)))
UtfString = UtfString.Replace(found, code)
match = re.Search(UtfString)
Loop
Return UtfString
End Function
1 Like
Or this:
Public Function ConvertUnicodeEncoded(source As String) As String
if source.Bytes < 6 then
//
// Not big enough
//
return source
end if
var sourceChars() as string = source.Split( "" )
var destChars() as string
for i as integer = 0 to sourceChars.LastIndex
var sourceChar as string = sourceChars( i )
var destChar as string = sourceChar
if sourceChar = "\" and ( sourceChars.LastIndex - i ) >= 6 then
var nextChar as string = sourceChars( i + 1 )
if StrComp( nextChar, "U", 0 ) = 0 then
var isGood as boolean = true
var hexArr() as string
for hexIndex as integer = i + 2 to i + 5
var hexChar as string = sourceChars( hexIndex )
if hexChar >= "a" and hexChar <= "f" or hexChar >= "0" and hexChar <= "9" then
hexArr.Add hexChar
else
isGood = false
exit for hexIndex
end if
next
if isGood then
var hexString as string = "&h" + String.FromArray( hexArr, "" )
var codeValue as integer = hexString.ToInteger
destChar = chr( codeValue )
i = i + 5
end if
end if
end if
destChars.Add destChar
next
return String.FromArray( destChars, "" )
End Function
But actually, both solutions suffer from the same problem: escaped slashes.
Consider the original string: “Use \U301 for the accent”. Encoded that would (probably) be “Use \U301 for the accent”. Both solutions would mess that up.
(Or maybe the slash would be converted to “\U005C” and it won’t be an issue.)
It will be escaped as \\U0301, and a solution can be
Private Function EscapedUnicodeToUTF8(escapedString As String) As String
Const escapeDoubleBackslashes As String = &uFFF9+"\"+&uFFFb
Var UtfString As String = escapedString.ReplaceAll("\\", escapeDoubleBackslashes)
Var re As new RegEx
Var match As RegExMatch
re.SearchPattern = "\\[Uu][0-9a-fA-F]{4,4}"
match = re.Search(UtfString)
Do until match = Nil
Var found, code As String
found = match.SubExpressionString(0)
code = Text.FromUnicodeCodepoint(Integer.FromHex(found.Middle(2)))
UtfString = UtfString.Replace(found, code)
match = re.Search(UtfString)
Loop
Return UtfString.ReplaceAll(escapeDoubleBackslashes, "\")
End Function
Beside being “right” (probably just because they are commonly used), wouldn’t it be time to remove one of these two ways to simplify things?
How do you propose to do that?
It could be that composing characters are essential in some non-Western languages - I don’t know enough about it. Apple seems to use decomposed characters, so that for example é is always made with the letter e followed by U+0301 (so, 65 CC 81 in UTF8). The composed é is U+00E9 or C3 A9 in UTF8.
You note that the decomposed é is three bytes in UTF8, and the composed é is two bytes. I don’t know why Apple does this but it’s perfectly valid UTF8 and all rendering engines should show the result as é. If they don’t then they are buggy. Personally I wish they hadn’t, but perhaps there are reasons I’m unaware of.
I’d say my propositions, if any, wouldn’t be smart. It’s up to the ones having the patent to make the changes. But discussing that is good.
I don’t know either, but since all composing characters can be made of decomposed ones, the OS could fairly well always use the decomposed version.
On my keyboard (Swiss-French), I can make “é” using both ways. There’s a straight “é” key but I can also use option+key-next-to-backspace (´) followed by “e” (é). I’ve never checked whether both ways lead to the same character. Could be interesting, I’ll check when I’ve time.
That’s often what we call “for compatibility purposes” (possibly). Both ways have existed since the beginning and it’s now too late to remove one easily; who knows whether that was a mistake in the first place and would have been better if the chose only the decomposed way?
Could you post your present code ?
I just created a field with accented characters in XCode:

Then I fed the saved plist into an Hex editor:

Amazingly enough, no backslash escape character there. Instead,
éèçàùâêîôûäëïöü
That is why it is important to know the method used to write to the plist.
Without knowing that, this discussion may get nowhere.
I try it but it just removes an antislash but does not convert unicodes characters of the accents !
s = EscapedUnicodeToUTF8(TextFieldName.Text)
MessageBox(s)
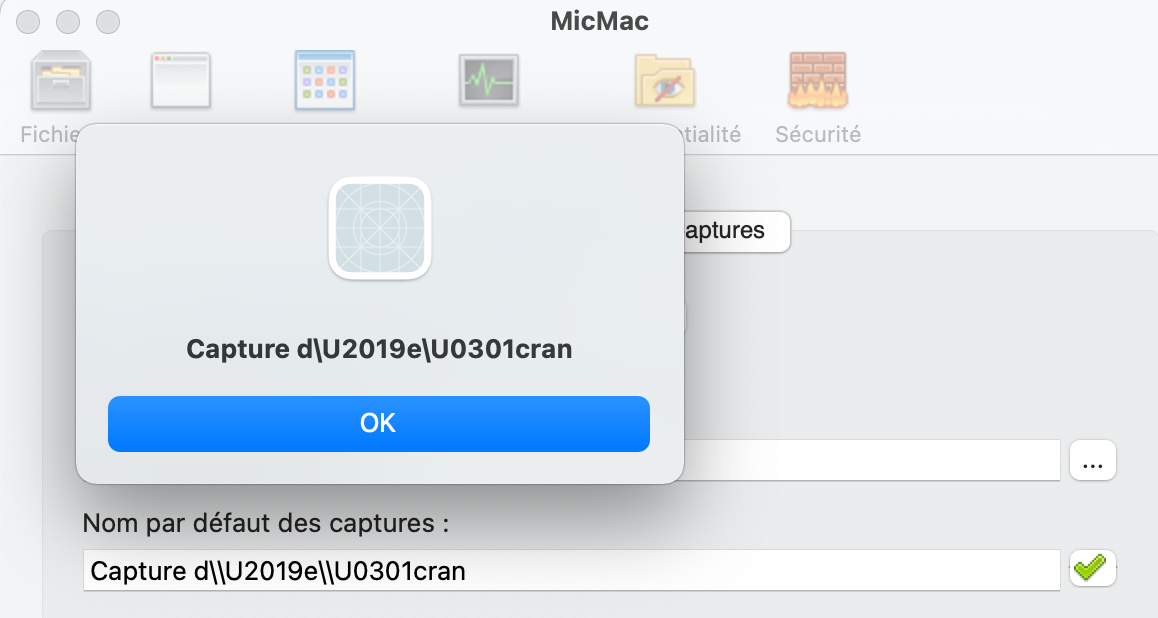
Finalement Michel, ca me semble trop complexe. Je me demande si je ne vais pas simplement “parser” la chaine caractère par caractère (dans un grand Case) et substituer les quelques caractères accentués par leur équivalent unicode. Et faire le contraire dans l’autre sens (moins évident).
du type : if machaine contient “é” : alors machaine = machaine + “\U0301”, etc.
We are not far away but it is not the right conversion. We have the apostrophe but not the emphasis on the “é”
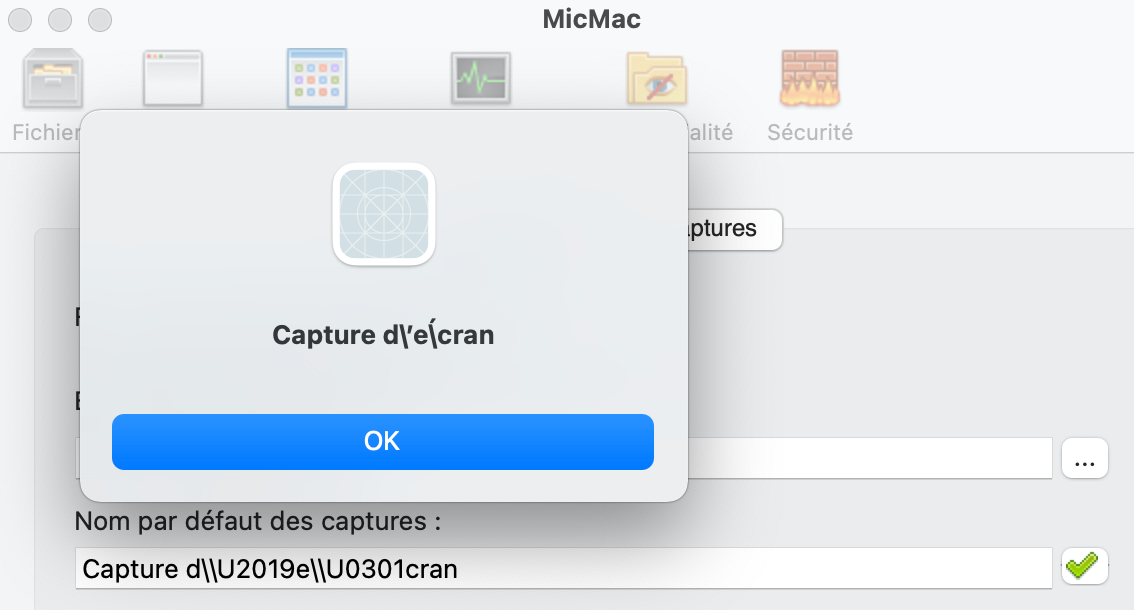
for info, result must be : “Capture d’écran”
Your hex editor is not correctly rendering the characters. Did you tell it that the content is UTF8? You see after the bytes for <string>, there is C3 A9, C3 A8 which are the composed UTF8 versions of é and è. But your hex editor is displaying such as √@ etc instead.
You are right. But in UTF8 No character is displayed. Probably the Hex editor does not support composited.

Why are you adding a second backslash? The function is treating correctly what you wrote.
EscapedUnicodeToUTF8("d\U2019e\U0301cran") -> "d’écran"
And correctly also
EscapedUnicodeToUTF8("d\\U2019e\\U0301cran") -> "d\U2019e\U0301cran"
Function code: How convert string to Unicode? - #29 by Rick_A