Ha, I bet that is Hex Fiend you are using. I just tried it too.
I typed in 3E C3 A9 C3 A8 C3 A7 65 CC 81 - and it displays like yours. But if you then select that hex and with the little menu at the bottom of the window choose UTF-8 then it displays it as UTF-8. I dunno why the right-hand column ignores all attempts to chasge the encoding it uses to display the hex.
Anyone here know why Apple seems to use decomposed UTF8 when making characters with accents?
I don’t know what Apple’s policy is, but there’s no good single solution to this.
One problem is that there are a vast number of possible combinations of letters and accents (more generally, diacritics), and only some of them exist as precomposed characters in Unicode. This means that to produce the composed normal form a program (or library) has to know which ones exist as composed characters. On the other hand, there can be characters with more than one diacritic. With decomposed characters, in which order should the accents appear? Some pairs of diacritics have a visible order - in some languages a character may have both a circumflex and an acute accent, it’s necessary to specify which way round they go. In other cases they don’t, such as a circumflex and a cedilla which by their nature go on the top and bottom (I doubt that particular example really occurs). Unicode therefore defines combining classes and a canonical ordering for combining characters to make it easier to compare two strings.
Thank you, I will test.
In the.plist file the unicodes are written each time with two Backslash (but only one is displayed in the forum, I don’t know why! Sorry). Can you make the change please ?
Private Function UnicodeEscapedStringToUTF8(escapedString As String, useDoubleBackslashes As Boolean = true) As String
// Convert the output of a MacOS "defaults read whatever" to proper UTF-8
// Unicode chars are encoded as "\\Uxxxx" where xxxx is the hex codepoint
// Passing useDoubleBackslashes = false it process it C style "\Uxxxx"
Const escapeDoubleBackslashes As String = &uFFF9+"\"+&uFFFb
Var UtfString As String = escapedString.ReplaceAll( _
If(useDoubleBackslashes, "\\\\", "\\" ), escapeDoubleBackslashes _
)
Var re As new RegEx
Var match As RegExMatch
re.SearchPattern = If(useDoubleBackslashes, "\\\\", "\\" )+"[Uu][0-9a-fA-F]{4,4}"
match = re.Search(UtfString)
Do until match = Nil
Var found, code As String
found = match.SubExpressionString(0)
code = Text.FromUnicodeCodepoint(Integer.FromHex(found.Right(4)))
UtfString = UtfString.Replace(found, code)
match = re.Search(UtfString)
Loop
Return UtfString.ReplaceAll(escapeDoubleBackslashes, "\")
End Function
Very sorry, I have a little problem ! the variable “ur” does not return the string identical to the plist!
Shell1.Execute ("defaults read com.apple.screencapture name")
//ud is CFString not a String
ud = Shell1.Result
//MessageBox(ud)
TextFieldName.Text = EscapedUnicodeToUTF8(ud, true)
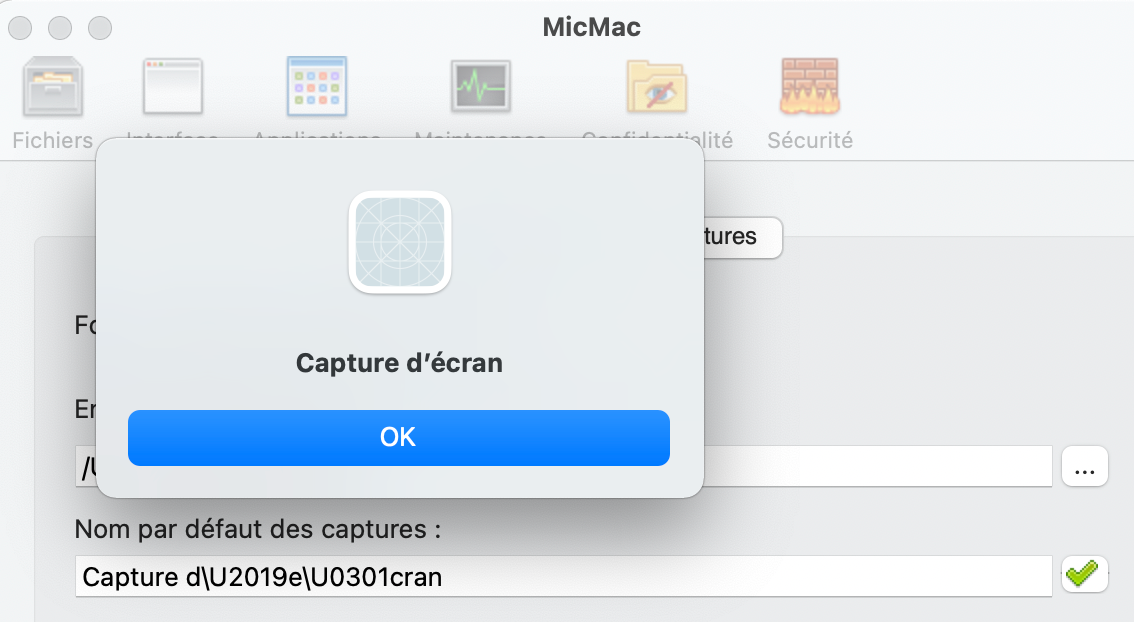
TextFieldName.Text = « Capture d’écran à Denis » .plist ‘name key’ = “Capture d’\U00e9cran \U00e0 Denis”; <—this has been converted
variable ud return = Capture d’\351cran \340 Denis !!! <----- But the unicodes to translate are these !
How you mistakenly informed us since the beginning that you had an encoding \Uhhhh and latter \\Uhhhh and now you say it was a mistake and it’s only \ooo ?
If are having a bad time trying to express yourself in English, write in French.
Yes, I will adapt my code to follow it. Apparently no “\U” in the results (\Asciii code)
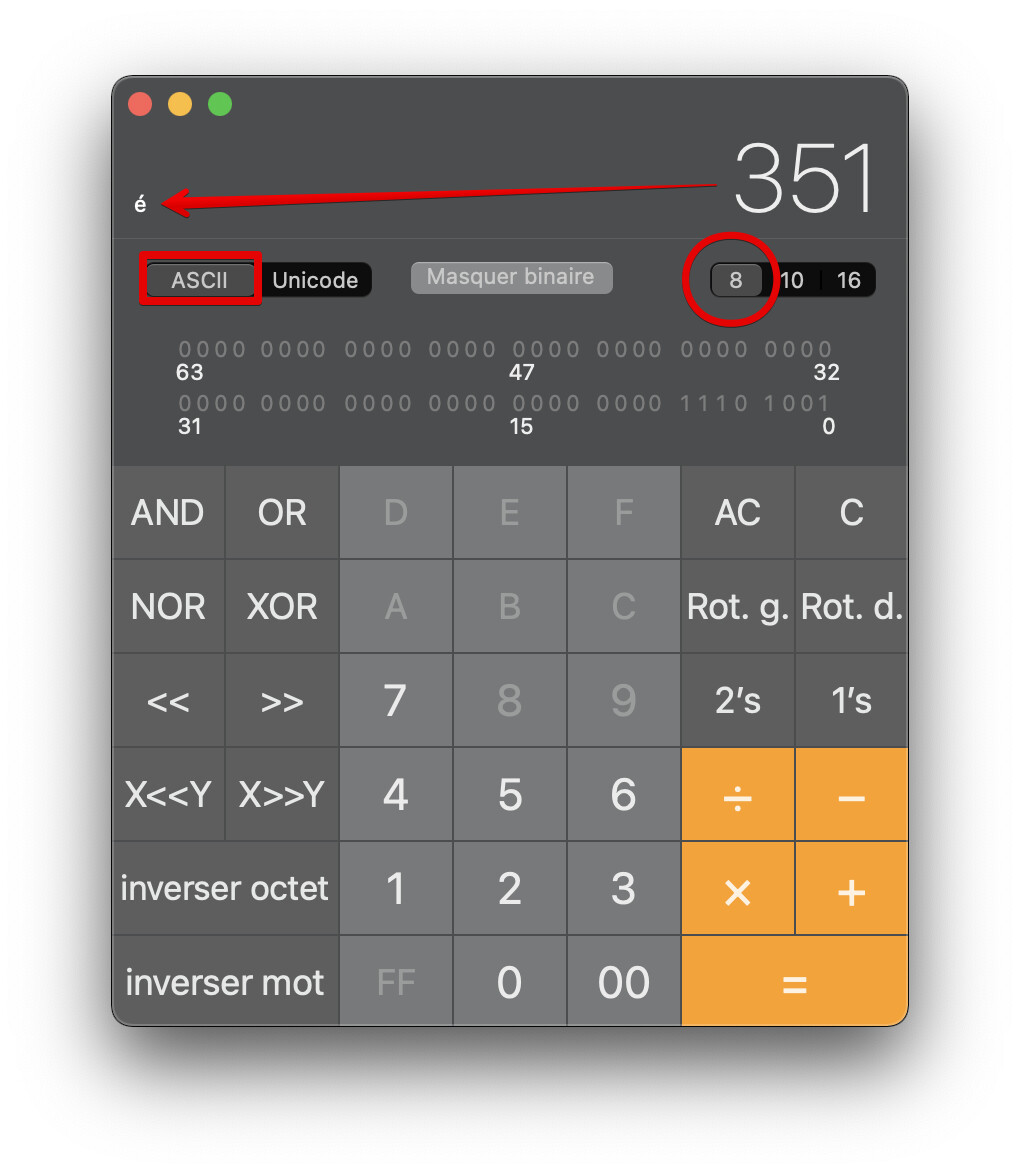
MessageBox(ur) gives “Capture \351cran \340 Denis”. Just this.
When a Unicode is higher than \377 it should (because max octal could reach \777) be encoded as \uhhhh (lowercase “u”). As those chars you used in your example didn’t, they used the short \ooo instead.
I think you just have to detect the antislash in the (ur) string and then convert each ascii value behind (chr(value)) to get the accented letter etc, going up the whole string.
Look :