Hi all,
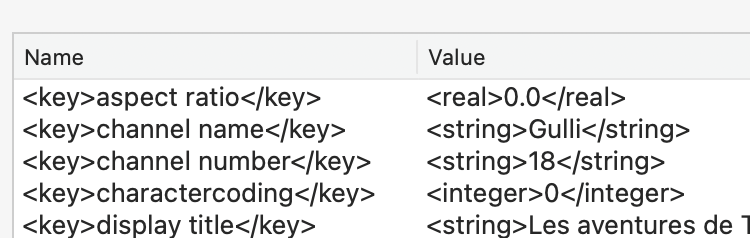
I have a file with this kind of data:
<key></key>
<string></string>
<key>actual duration</key>
<real>1333.72</real>
<key>actual start time</key>
<date>2021-09-21T20:28:27Z</date>
<key>aspect ratio</key>
<real>0.0</real>
I can get and too.
I can read:

or “key”, but not the Names nor Values…
I searched in the documentation and all I found is to get <key names=“Filou” id=“idiot”.
I was feeling to quest the graal.
What is the instruction to get the tag value ?
Help !
No, I do not want to display nor nor …
It may be me, but that looks like a crazy way to store data in XML
How is the reader expected to know the type of the data that ‘follows’ a key entry?
I would have expected
<key actual start time=“2021-09-21T20:28:27Z” "/>
That way, you can use XQL to get all the nodes which are keys.
And check to see if they have a start time, aspect ratio, etc
If you get all they key nodes from this file, all you get is a list of names. The data ‘about’ that item is not part of the node.
I hope there is a way to get what you want, but I dont know what it would be.
I’d probably use Grep, or split the data on <key>
actual duration</key><real>1333.72</real>
actual start time</key><date>2021-09-21T20:28:27Z</date>
aspect ratio</key><real>0.0</real>
split each string on </key>
actual duration , <real>1333.72</real>
actual start time, <date>2021-09-21T20:28:27Z</date>
aspect ratio, <real>0.0</real>
which you could turn into a dictionary.
I really hope there is a better solution
This is a commercial software that creates this file (these files)…
Extracting “old school” the data: that is what I do not wanted to do, but if this is the solution… I already do it with html, I can do it here.
Nothing fancy, just time consuming.
But I recall, old xml was capable of doing that (if my memory is correct). That is why I stopped when I do not found how to do it n the documentation. I may (when we will have a sunny day) make a search for where I placed my “How do I do with xml and REALbasic“ papers… in the archive box.
Thank you Jeff.
PS: have-you checked the mirror web site (talking about a crazy way to store data…) Same image stored at different size / cropped (especially cartoons), same strip two consecutive days, many days with no strips in the archives (now, but they had them some years ago), webp or jpg files (who will you get is like a lottery: sometimes the former, sometimes the later…) etc.
I early forget… 2048 is the max width for the cartoons, but if you type in, the URL 1227b instead of 2048, you will get a larger cartoon (in that case, you are asking the height of the file); both parameters are coded as: /s2048/ or /s1227b/.
Once you know…
Here’s a link to todays’s Andy Capp
Oh: the link have a .jpg extension, but the file is .webp 
Enjoy it.
You could use the XMLReader class to read the file into a dictionary. Create a class with a super of XMLReader.
Add StartElement method. It will be called for each of the XML open tags. So in your example it would be called with < key > followed by < string >, < key > followed by < real > etc (spaced to prevent the HTML swallowing the code).
Add a Characters method. It will be called for each of the strings between the < ></ > key pairs. My using properties for the class to hold the current Key and “value” (real, date etc). you could then build a dictionary.
The following is pseudocode but it should get you started. Once you get your head around how it works you can see it’s a lot easier than the other way of reading XML. It doesn’t cause memory problems with large files either, as it chunk reads them.
Class MyDocumentReader Parent XMLReader
Property WithinKey as Boolean = false
Property CurrentKey as String
Property ValueType as String
Property dicResult as Dictionary
Event StartDocument
dicResult = New Dictionary
End Event
Event StartElement( name As String, attributeList As XMLAttributeList )
Select case name
Case "key"
WithinKey = True
case else
WithinKey = False
ValueType = name
End select
End Event
Event Characters( s As String )
if WithinKey then
CurrentKey = s
else
select case ValueType
Case "real"
dicResult.Value( CurrentKey ) = val( s )
case "date"
var dDateTime as New DateTime
dDateTime.SQLDateTime = s
dicResult.Value( CurrentKey ) = val( dDateTime )
case "other types as required"
end if
End Event
// Call it as follows:
var oXMLReader = new MyDocumentReader
oXMLReader.Parse( FolderItem )
var myResult as Dictionary = oXMLReader.dicResult
1 Like
Hi Ian,
thank you for your documented with example answer.
I came back to give a feed back.
To my previous code, I added in less than 5 minutes the following code:
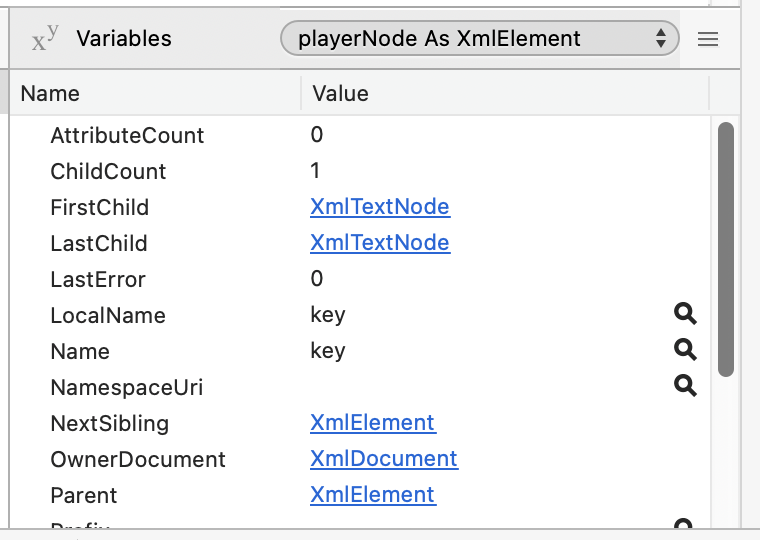
playerNode = teamNode.Child(player)
// Holds: “<key>actual duration</key>”
ItemName = playerNode.ToString
ItemName = ItemName.NthField(">",2)
ItemName = ItemName.NthField("<",1)
playerNode = teamNode.Child(player+1)
ItemValue = playerNode.ToString
ItemValue = ItemValue.NthField(">",2)
ItemValue = ItemValue.NthField("<",1)
// Report what I found in a ListBox
LB.AddRow(ItemName, ItemValue)
and report the results (not changed part) into a ListBox:

The addded code are the 2 x 2 lines with NthField.
So long as there are no < or > within your key values or strings.
Why will there be some ?
At least, if there are some, I ask for the Node.Name and build the search using the whole tag adding leading < and ending > to Node.Name.
Of course, the test file does not have, but who knows ? In a description field for example.
I’ve no idea, but nthfield will fail if there are. String hacking just seems a bad approach when there are two built in methods specifically for dealing with XML.
His contents aren’t usual XML, more like an unstructured “XML like tagged content”.
Have you tried what you wrote? I haven’t, but I do expect some parsing error with Emile’s content.
It’s just pseudocode. Events aren’t defined that way. String to date is likely not formatted correctly to work correctly. However the basic principles are correct.
The format is somewhat similar to an Apple plist file.
Do you mean like getting the value "1333.72 " of the real line?
To be a valid XML first it needs a main node which inlcudes all other nodes, like <root></root> and of course the xml-declaration tag: <?xml version="1.0" encoding="UTF-8"?>
The value of the real number is here a child textnode of the tag node, i made a little sample.
XML_textnode.xojo_binary_project.zip (5.7 KB)
Thank you all, Thomas.
Now I know what to search and so I searched (to know why I do not found it when I do).
In Xojo 2021r2.1: XMLTextNode appears in the See Also part, last words: XMLTextNode classes.
And typing TextNode in the search field is transformed to Text… (just like TextInputStream and TextOutputStream; but I remember these two exists and that made the difference).
That is why I took the xml way, but with bad documentation and memory it was hard to achieve the job, thus the help call.
That is why I never trashed the REALbasic XML documentation I printed so long ago (20 years or so); but I do not know where is is (ongoing relocation).
The screen shot below of the debug sessions shows:
So, I need to get playerNode.FirstChild as XMLElement (a click in XMLTextNode display the information I want), but I failed to find a solution.
I even go to www.w3schools.com in vain (explanation on how to write good xml, but no code to read it).
Time for meal.
What did you tried, some XML source and sample code?
I guess XQL/XPath would be a good way to go
https://documentation.xojo.com/api/text/xml/xmldocument.html#xmldocument-xql
I loved the link to “www.w3schools.com” in the documentation.
They have instructions that are missing in Xojo xml implementation:
getElementById()
getElementsByTagName()
and they use as example code that is similar to what I have. Few attributes (I have none) and texts inside tags.
From w3Schools:
If you place a character like "<" inside an XML element, it will generate an error because the parser interprets it as the start of a new element.
So, having “>” or “<” in text is already an error. The page is here, search for Entity References and read below.
One thing I forgot to mention is that I do not care about the “kind” of data. I mean: for me a date is a date well or not well formed; an integer or a real is just a number, etc. These are for the original software who use these data (read and write). I will extract the data I need and display them in certain design. Nothing related to development. And the date holds a T as a delimiter between date and Time… Nice; better than a nbsp… character.
I also will have to load an image to place beside the data (and that image is in the same folder, an easy taken file (same file name, different file extension).
Fortunately, “Time is on my side”.
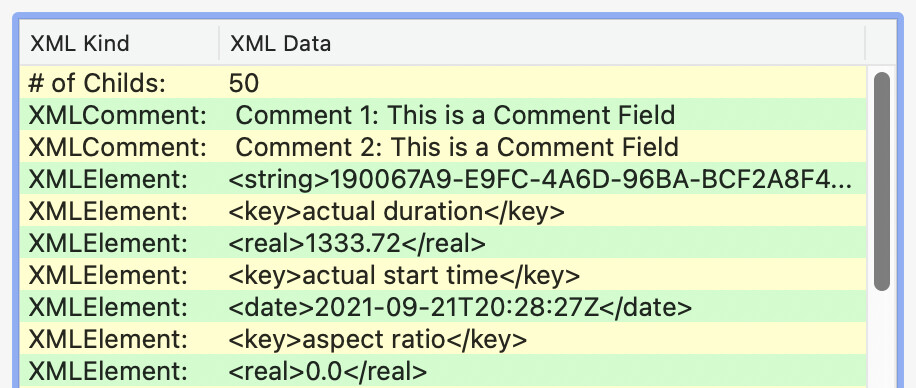
I add two comments lines to the test file.
I also add a button to report what’sin the xml root:
As you can read, comments are correctly displayed (first two lines of root), and everything else are XMLElement.
The code in the button explore root and report what is found using If xxx ISA XMLComment, XMLElement, etc.
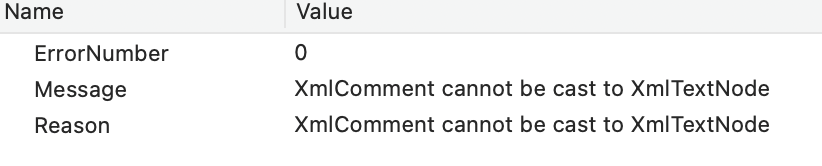
BTW: I tried to cast the node, but this is Illegal:
Var foo As New XMLTextNode
foo = XMLTextNode(fatherNode.Child(Root_Idx))
I get the Exception at run time.
Same for XMLElement.
I used:
For Root_Idx = 0 To fatherNode.ChildCount - 1
// Get a Node
sonNode = fatherNode.Child(Root_Idx)
If sonNode IsA XMLComment Then
LB.AddRow "XMLComment: ", sonNode.Value
ElseIf sonNode IsA XMLElement Then
LB.AddRow "XMLElement: ", sonNode.ToString
ElseIf sonNode IsA XmlNode Then
LB.AddRow "XMLNode: ", sonNode.ToString
ElseIf sonNode IsA XmlNodeList Then
LB.AddRow "XmlNodeList: ", sonNode.ToString
ElseIf sonNode IsA XMLTextNode Then
LB.AddRow "XMLTextNode: ", sonNode.Value
Else
LB.AddRow "Other Node: ", sonNode.ToString
End If
// To avoid infinite loop
If UserCancelled Then Exit
Next
to fill the ListBox (screen shot above).
Remove the two Comment lines (that I add on purpose for this test), everything is XMLElement.
As far as i can see: You forgot to traverse the possible childs of every node via a recursive aproach.
Hm, no, seems something else. Can you share the sample test project, would make it easier.
{kind=link}