u.name is a string property of a Class represented by “u”
Porting to the new API, the old code was:
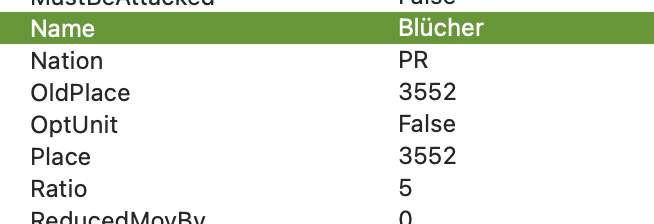
elseif u.name.toText = "Blücher" then
Xojo does not accept changing it to:
elseif u.name.toString = "Blücher" then
If comparing the strings directly:
elseif u.name = "Blücher" then
the strings don’t match. This issue occurs after saving/loading from an SQLite database. Using toText again and ignoring the deprecated warning makes it work. This is likely an encoding conflict with the “ü” character probably…
Basically your problem seems to be that the data in the database uses non-composed characters, whereas Xojo is assuming composed characters.
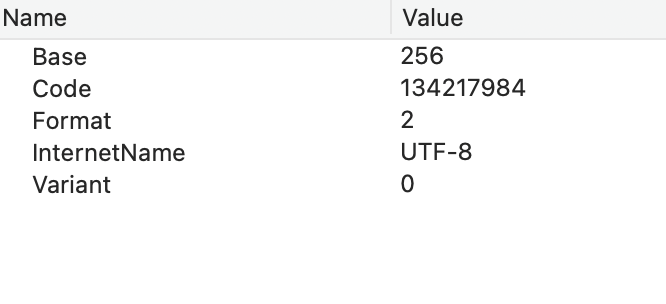
The ü is not composed, in the database - it’s a simple u followed by a composing umlaut (so, two code points, 3 bytes), which will appear the same on-screen as the single code point ü (two bytes). How did the data get into the database?
Right, that’s exactly what Tim has been explaining: those two strings appear the same when printed to the screen, but the underlying bytes are different, and thus the string compare function isn’t behaving as expected.
Go follow that link that I posted and download the Unicode module. Normalize both of your strings and then compare them; you should find that they compare properly.
Honestly I think this is a flaw in how strings are compared, whether that’s in the Unicode specification; the OS’s implementation; or Xojo’s internal implementation. Decomposed characters should equate to their composed representations. I don’t know why it is done this way.
May it be considered a bug?
Made the following test::
var enc as TextEncoding = u.name.Encoding
var source as string = "Blücher"
var enc2 as TextEncoding = source.Encoding
source = source.DefineEncoding(enc)
if u.name = source then
break
end if