Some years back we were all being encouraged to switch from String to Text (now deprecated). Part of the reason, I seem to recall, had to do with some deficiencies that String might suffer from in its handling of UTF8. Such as perhaps not being able to properly handle the longer multi-byte characters. I’m a bit hazy about this so would appreciate anyone’s recollections.
I have a method which searches through the characters of a string, and a user now reports, after some years without a problem, it giving an OutOfBoundsException. My unit tests seem to work OK, but perhaps the data being fed to in the user’s case is bad in some way so that ordinary String methods behave badly.
I gave the user a special version which catches the exception and writes everything to a log file, but he just deleted the bad data instead of sending me the log. So I’m working a bit in the dark here.
Sub textfromhtml (hb as String) As String
// Returns the supplied html body with all HTML elements removed. Also are replaced by a
// space. <style> elements are detected and everything between <style> and </style> is removed.
// Note that the output doesn't have to look pretty as it will only be used to calculate a
// spam score.
Var i, loc, startind, stylend, len, top As Integer, bodchrs(), outchrs() as String, exitfl, innerfl As Boolean
Var bodtxt As String, re As RegEx, ro As RegExOptions
loc = 0 // Start at the beginning
bodchrs = hb.split ("") // Copy the body as an array
exitfl = False
len = bodchrs.LastIndex
while (True) // Loop looking for elements
startind = bodchrs.IndexOf ("<", loc) // Look for opening <
if (startind=-1) then // Not found, prepare for exit
exitfl = True
startind = bodchrs.LastIndex + 1 // Will want to copy to the end
end if
if (startind>loc) then // Found some text
top = startind - 1
for i=loc to top // So copy those chars
outchrs.Add (bodchrs(i))
next
if (exitfl=True) then Exit // We'd reached the end
outchrs.Add (" ") // Insert a space to keep text separated
end if
loc = bodchrs.IndexOf (">", startind) // Look for closing >
if (loc=-1 or loc=bodchrs.LastIndex) then Exit // Does not exist, give up
i = startind // Check if the element was a <style>
if (bodchrs(i+1)<>"s" or bodchrs(i+2)<>"t" or bodchrs(i+3)<>"y" or bodchrs(i+4)<>"l" or bodchrs(i+5)<>"e") then
loc = loc + 1
Continue // Not a style element
end if
loc = i + 6 // Go past <style
innerfl = False
while (True) // Now look for a </style> element
stylend = bodchrs.IndexOf ("<", loc) // Look for next <
if (stylend=-1) then // Not found, just exit
innerfl = True
Exit
end if
i = stylend
if (len<(i+8)) then // Not enough chars left to examine
innerfl = True
Exit
end if
loc = bodchrs.IndexOf (">", stylend) // Look for closing >
if (bodchrs(i+1)="/" and bodchrs(i+2)="s" and bodchrs(i+3)="t" and bodchrs(i+4)="y" and bodchrs(i+5)="l" and bodchrs(i+6)="e") then
if (loc=-1 or loc=bodchrs.LastIndex) then innerfl = True // Does not exist, give up
loc = loc + 1
Exit // Take us past the end of the </style>
end if
loc = loc + 1
wend
if (innerfl=True) then Exit
wend
bodtxt = String.FromArray(outchrs, "").ReplaceAll(" ", " ")
ro = new RegExOptions
ro.CaseSensitive = False
ro.ReplaceAllMatches = True
re = new RegEx
re.Options = ro
re.SearchPattern = "\s+"
re.ReplacementPattern = " "
Return re.Replace(bodtxt).trim ()
Whatever the cause of your issues, I doubt it has anything to do with encoding unless the string is coming in with some multi-byte encoding like UTF-16 and is not labelled as such.
That is, Xojo thinks the UTF-16 encoded string is UTF-8, or doesn’t know what it is (encoding is nil).
(Remember, encoding tells Xojo how to interpret the bytes within the string, much like a file extension tells your computer how to open a file.)
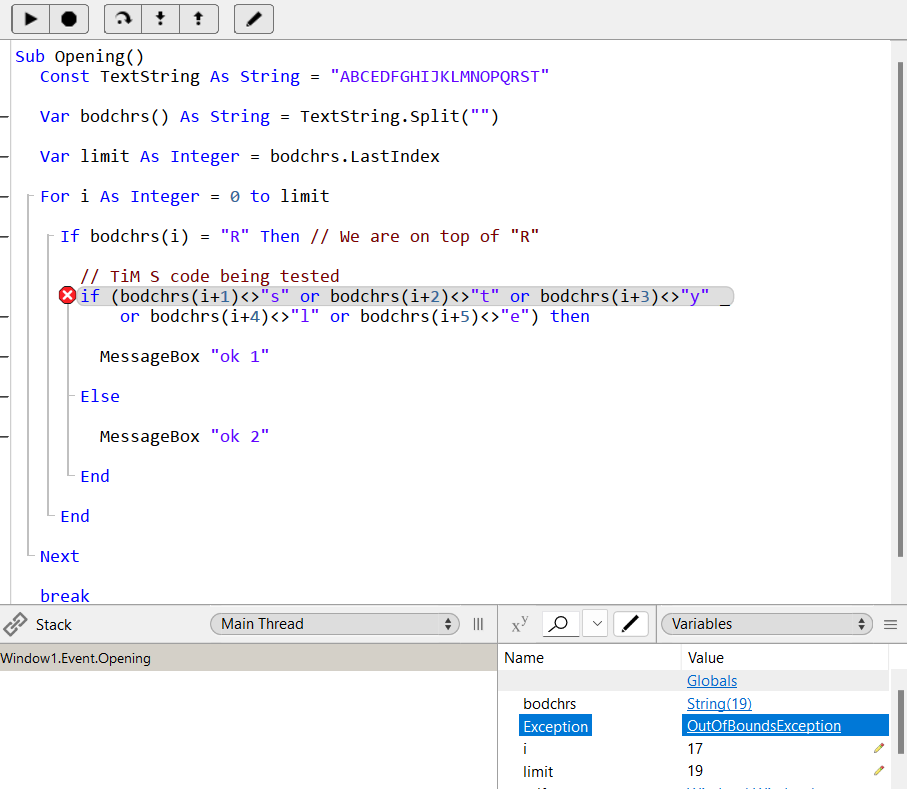
Const TextString As String = "ABCEDFGHIJKLMNOPQRST"
Var bodchrs() As String = TextString.Split("")
Var limit As Integer = bodchrs.LastIndex
For i As Integer = 0 to limit
If bodchrs(i) = "R" Then // We are on top of "R"
// TiM S code being tested
if (bodchrs(i+1)<>"s" or bodchrs(i+2)<>"t" or bodchrs(i+3)<>"y" _
or bodchrs(i+4)<>"l" or bodchrs(i+5)<>"e") then
MessageBox "ok 1"
Else
MessageBox "ok 2"
End
End
Next
break
How to fix? Many ways, but just adding a guard code you will protect the range as:
Const TextString As String = "ABCEDFGHIJKLMNOPQRST"
Var bodchrs() As String = TextString.Split("")
Var limit As Integer = bodchrs.LastIndex
For i As Integer = 0 to limit
If bodchrs(i) = "R" Then // We are on top of "R"
// TiM S code being tested
If i+5 <= limit Then // guard code
if (bodchrs(i+1)<>"s" or bodchrs(i+2)<>"t" or bodchrs(i+3)<>"y" _
or bodchrs(i+4)<>"l" or bodchrs(i+5)<>"e") then
MessageBox "ok 1"
End
End
End
Next
break
Your test is interesting but irrelevant. You can always break any method by extracting a part of it. I’m looking for an ordinary piece of html (or badly formed html, perhaps) that breaks my method, not just some part of it. Such would be useful to me, in fact.
Such would not surprise me at all. Dealing with unsolicited input data such as an email is made harder by the fact the servers (a) lie about encodings or (b) don’t bother to follow the RFCs or (c) define their own additions.
This remember me one case I always remember, I probably already wrote it here few years ago, maybe. I was at a meeting, someone presenting a code and explaining what he would be doing to process something and I noticed a possible fail in a extreme case and said “But what if it receives a 0 (zero) as input?” and the answer was “We will never will a get a zero there” (no guard code for such exception). Few weeks later we had crashes… a zero got there.
and in fact giving me something else. If the user ever sends me the log file and I can pin the issue down to this sort of issue, then I may rewrite this using SplitB rather than Split or perhaps copy to a memoryblock. But I have other things to focus on, which is why I was curious about Text vs. String, and what was supposedly wrong with String such that we were encouraged to embrace Text.
Thanks. This was only meant to be a simple method that gets rid of most stuff. And as the comments say, the output is used to calculate a spam score. I’m not going to worry if that’s off by a point or two. An OOBE, however is more important.
First, I’m not aware of any overtly nasty bugs in Xojo’s handling of UTF-8 data in String. It’s such an overwhelmingly popular use case that I would assume almost all of the bugs would have been identified and smooshed by now. You’ll note that the replies to your post have breezed right past your question about Strings vs Text, because it doesn’t seem to be relevant; you’re using String, so let’s figure out why that isn’t working. Maybe there really is a bug in String that you are somehow triggering.
Second - in this situation, where (possibly) bad data is causing your code to crash, you have two options:
Get your hands on the data triggering the issue
…and if that isn’t possible…
Go through your code and eliminate all the possible errors, even those which you don’t think could be the problem. Throw out your assumptions about the incoming data, because one of them is wrong and you don’t know which one it is. Add checks and logging for every conceivable corner case.
To briefly address your question about Text: Text was supposed to be a partial replacement for String that explicitly ONLY handles textual data with a specified text encoding. The String datatype allows a Nil text encoding and can be used to store and manipulate arbitrary binary data; Text would not.
Text failed and is now deprecated for a variety of reasons, most prominently the fact that String wasn’t removed. The code changes required to transition code from String to Text were considerable, and since String was still a part of the framework and used all over the place, there was little incentive to switch. It drove everybody crazy trying to use Text and String in the same project until Xojo decided it wasn’t worth the effort and deprecated it.