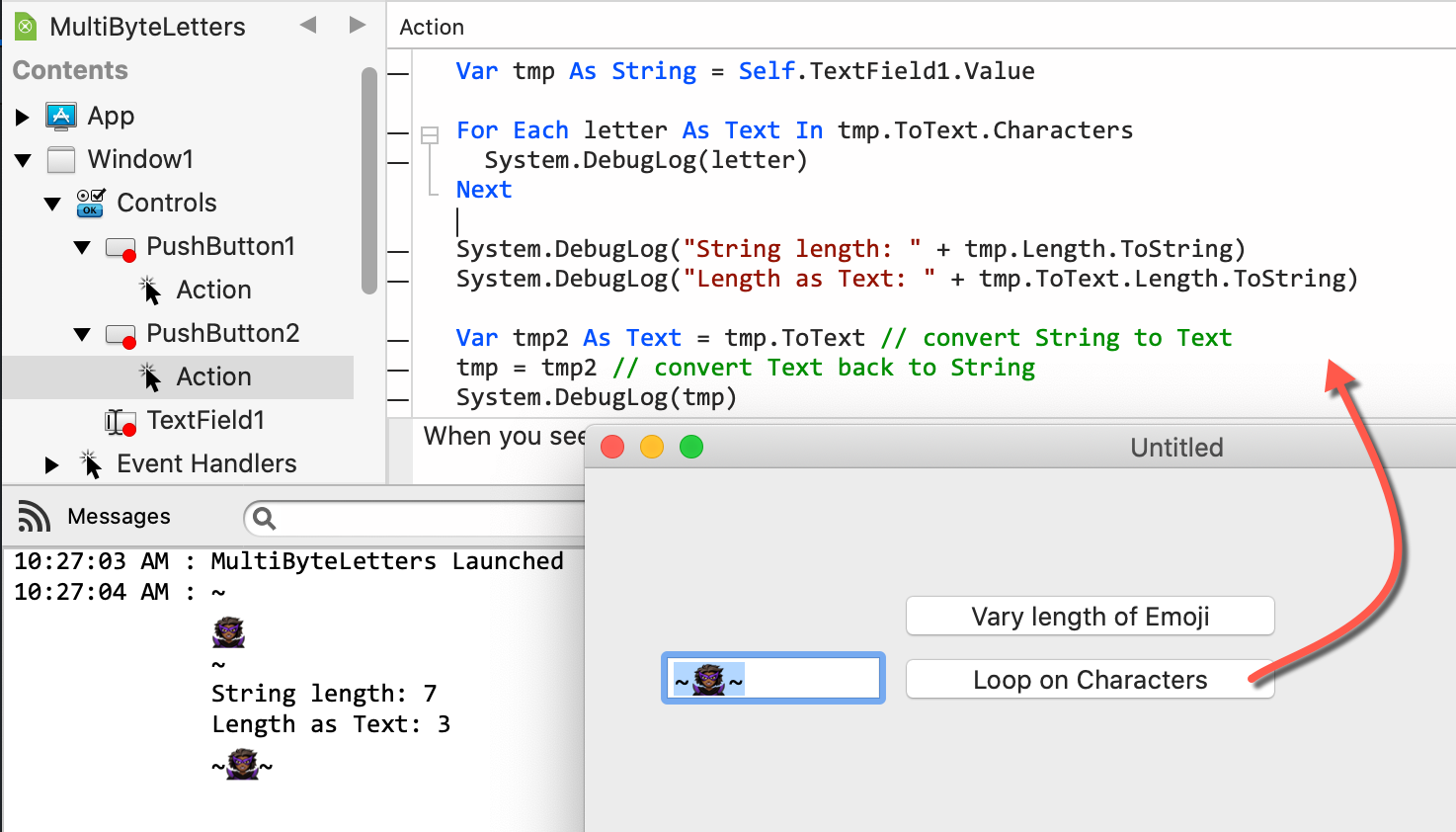
i split a string into single letters and then do further work with the returned array. Now a string may contain multibyte characters (see emoji in the code example). But the String.Split/String.SplitBytes method produces two characters from the emoji. Is there a way to bypass this and really get only one character back, the whole emoji? This question comes up when using String.Left/String.Middle, because even with a wrong index only the original emoji could be returned if you forget to read the second byte. The Japanese alphabet (I think the Thai one too) is also encoded with two characters. Do you have any tips or solutions?
[h]First Sample[/h]
[code]Const kText As String = “Hello World!” ’ please add a multi-byte Emoji within the String
Var letters() As String = kText.Split("")
For Each letter As String in Letters
System.DebugLog(letter)
Next[/code]
[h]Second Sample[/h]
[code]Const kText As String = “Hello World!” ’ please replace “Hello World!” with a multi-byte Emoji
Var s1 As String = kText.Left(1) ’ returns partial of the multi-byte letter
Var s2 As String = kText.Left(2) ’ returns the whole multi-byte letter[/code] Note: The forum only allows the display of single-byte emojis. Please try the code with a multi-byte emoji!
Text was specifically designed to handle text. String is not. The feedback case you really want to make is “Please bring Text into API 2.0” as the two function differently and you would get much more use out of the Text type. The hard part will be reminding Xojo that they should not remove String this time.
I know Tim. But I don’t think Xojo will keep the text type, also because it is slower than string and never really accepted by the users. Similar to the Auto Type.
Not that I have a solution for you @Martin Trippensee (my apologies about that), but I find this interesting how this these skin-tone/gender changing emojis are achieved (from a technical point of view).
The various combinations of characters required (and identify when they should be combined) to make them dynamic must certainly add to the complexity of the logic required to correctly represent them when viewed as textual information.
"…The Woman Supervillain: Medium-Dark Skin Tone emoji is a sequence of the Supervillain, Emoji Modifier Fitzpatrick Type-5 and Female Sign emojis. These are combined using a zero width joiner between each character and display as a single emoji on supported platforms.
When I saw how many characters were required for each emoji, you can alter the appearance of the emoji by limiting how many of the multibyte characters you include in your output.
Again, my apologies that I don’t have a solution for you.
Edited: because including the emojis in the post somehow truncated what I wrote.
I havent tried your example, but if your text is UTF-8 then from experience, Split will be working correctly. It just isnt doing what you want.
Have you tried converting your string to UTF-32 and then manipulating it?
This is interesting to read. I think @Tim Parnell was right upstairs. The problem seems to be that string was not primarily designed for text processing, but this is extremely important because the Text Type is deprecated. Xojo should take care of this, where they are currently making the String Type available on mobile platforms and add this functionality to API 2.0.
[quote=472253:@Kevin Gale]I havent tried your example, but if your text is UTF-8 then from experience, Split will be working correctly. It just isnt doing what you want.
Have you tried converting your string to UTF-32 and then manipulating it?[/quote]
Thanks for your input Kevin. I tried it, but this returns nonsense for Encodings.UTF32/Encodings.UTF32BE/Encodings.UTF32LE.
For what it’s worth, at this time, the documentation does not say the Text type is deprecated.
There are also some notes in the String page about converting back and forth between Text and String.
Even reading the Emoji from a TextField (as a String type) and converting to Text, then back to String again appears to have no ill affect on the Emoji (and presumably the underlying Unicode information).
Obviously, in an ideal scenario, the String type would also have a Characters method like Text does. In the meantime, I hope converting back and forth can help as a possible (temporary) solution.
[quote=472294:@Martin Trippensee]
Thanks for your input Kevin. I tried it, but this returns nonsense for Encodings.[/quote]
Yeh, I realised afterwards that what you need is the ability to work with grapheme clusters (user perceived characters) rather than Unicode code points (which is what the current string functions do). For us, the current string functions work exactly how we need them to but I do see a need to work with text at a higher level.
Rather than this being a bug I think there needs to be an enhancement to String to support the relevant functions from Text that work with grapheme clusters.
If you only need this for macOS and have access to the MBS plug-ins then the following code I hacked up should split a string the way you want it. If you don’t have access to the MBS plug-ins then you might be able to replace CFStringMBS with something in macOSlib.
Structure CFRange
location As Integer
length As Integer
End Structure
[code]Public Sub Test()
Dim s As String
Dim a(-1) As String
urgh!
It looks like the forum has mangled by post containing the sample as there should be a lot more code in the Test() method.
Let me know if you are still interested and i’ll re-create it.
I had the same problem earlier. I think it was the special emoji characters themselves.
But I did get an email from the forum of your post, that appears to contain everything. I’ll paste it here (minus the emoji).
[code]Public Sub Test()
Dim s As String
Dim a(-1) As String
s = “HelloThere”
'splits the string into unicode points
a = Split(s, “”)
'splits the string into grapheme clusters (user perceived characters)
Declare function CFStringGetRangeOfComposedCharactersAtIndex lib “CoreFoundation” (inString As Ptr, index As Integer) As CFRange
Dim cfStringObj As CFStringMBS
Dim count, i As Int32
Dim cfa(-1) As String
Dim theRange As CFRange
cfStringObj = New CFStringMBS(ConvertEncoding(s, Encodings.UTF16))
count = cfStringObj.Len - 1
i = 0
While i <= count
theRange = CFStringGetRangeOfComposedCharactersAtIndex(Ptr(cfStringObj.Handle), i)
cfa.Append(cfStringObj.Mid(theRange.location, theRange.length))
i = i + theRange.length