The email says that it’s windows-1252 encoding. But it’s not. I tried to do some goggling what type of Mojibake the above email is. But I wasn’t able to find anything that fits. For instance:
‰ → ä
¸ → ü
This is not ISO 8859-1 and not Windows-1252 either. Of course, I can brute force this as far as I can identify the characters. But I don’t have a clue what “— is.
Which encoding is it? If possible I need to be able to recognise the misencoding quickly. If not, I can make the user a menu item to fix the mojibake for the selected emails.
From earlier problems I remember that I need to do a ConvertEncoding and then a DefineEncoding.
I would say its the other way around, first DefineEncoding then ConvertEncoding…
Since you start with unknown encoding…so if you do not use DefineEncoding then its just BinaryData (or Default encoding in best case). Which would make ConvertEncoding have no clue what to do.
Once encoding is defined correctly then you can convert.
If you did it the other way around like you describe…then your converting something unknown and ConvertEncoding has no base to do things correctly. (And of course DefineEncoding following a Convert encoding does nothing at all since ConvertEncoding already will have stamped it with the encoding it converted to)
Nope. Fixing Mojibake definitively is first ConvertEncoding and then DefineEncoding because the text is screwed up. This ain’t my first rodeo with Mojibake. I just need to know which encoding my text is.
Below is some code which fixes a simple sort of Mojibake. Notice the order of ConvertEncoding and DefineEncoding:
// this function works only on UTF-8 text!
if not theLeft.HasHighASCII_MTC then Return Nil
if not encodings.UTF8.IsValidData(theLeft) then Return Nil
// how many ? do we have?
dim CountFieldsS as Integer = CountFieldsB(theLeft, "?")
if CountFieldsS = 1 then Return Nil
for currentEncoding as integer = 0 to Encodings.Count - 1
dim EncodingInternetName as String = Encodings.Item(currentEncoding).internetName
'try utf and iso first
if EncodingInternetName.left(3) <> "ISO" then continue
// now convert back to old encoding
dim newString as string = ConvertEncoding(theLeft, Encodings.Item(currentEncoding)) '<---convert
if not encodings.UTF8.IsValidData(newString) then Continue
// looks like the new text is valid UTF-8
dim CountFieldsT as integer = CountFieldsB(newString, "?")
if CountFieldsT = CountFieldsS then
newString = newString.DefineEncoding(Encodings.UTF8)
if newString.Length < theLeft.Length then Return Encodings.Item(currentEncoding)
end if
// and conversion didn't find characters it didn't like
next
You will eventually crash if you do ConvertEncoding on the unknown. (Especially on Windows systems). Its more or less matter of luck if doing ConvertEncoding first.
(Same if you feed false promise to it before converting, as in DefineEncoding, defining it as something other than what it actually is)
Nope. And not using Windows. Again, this is not my first rodeo with Mojibake. I do extensive analysis of the emails.
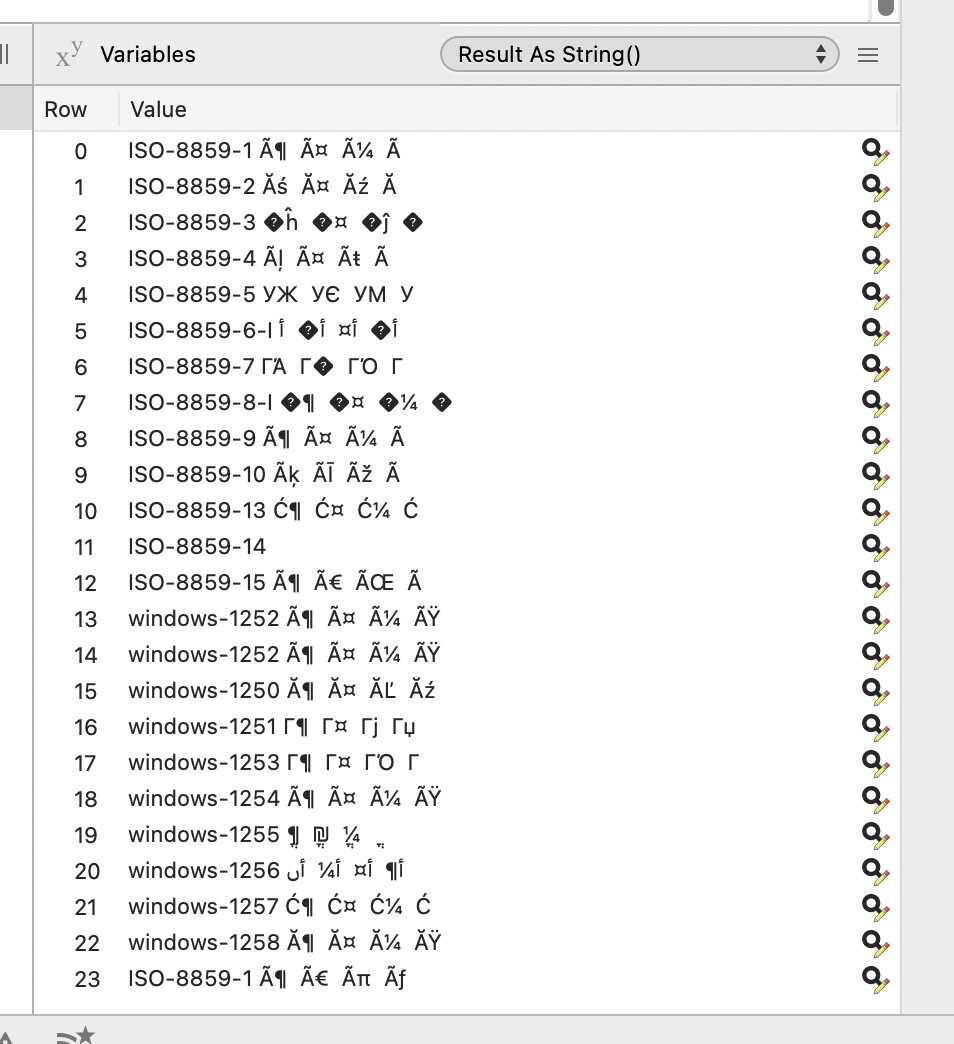
Whatever encoding my text is it’s weird. I tried adapting the above code to my text. I made a list of encodings where the text isn’t empty and doesn’t have “?”. But the result is an empty list:
dim theLeft as String = Untitled
for currentEncoding as integer = 0 to Encodings.Count - 1
dim EncodingInternetName as String = Encodings.Item(currentEncoding).internetName
dim newString as string = ConvertEncoding(theLeft, Encodings.Item(currentEncoding)) '<---convert
if not encodings.UTF8.IsValidData(newString) then Continue
newString = newString.DefineEncoding(Encodings.UTF8)
if newString.Length = 0 then Continue
if CountFieldsB(newString, "?") > 0 then Continue
Result.Add(newString)
EncodingsList.Add(EncodingInternetName)
next
You could call the unix ‘file’ command to see if it can figure out the encoding.
This code runs on a Mac. Windows may not have this available:
Public Function GuessEncoding(Txt As String) as string
'Call the unix/linux file command in a shell to guess the encoding of the input text
'First, save the suspect text in a temporary file
dim f As FolderItem = SpecialFolder.ApplicationData.Child("MyAppStuff")
if not f.Exists then
'Create Application Support/MyAppStuff folder.
f.CreateAsFolder
end if
dim sPath As String = f.NativePath
If f <> Nil Then
Dim tf As FolderItem = f.Child("mytemptestfile.txt")
If tf <> Nil Then
Try
Dim t As TextOutputStream = TextOutputStream.Create(tf)
t.Write(Txt)
t.Close
Catch e As IOException
' Oops...
End Try
End If
End If
'Now run the 'file' command in the shell script
Dim My_Shell As New Shell
My_Shell.TimeOut=-1
Dim theShellCode As String = "cd """+sPath+""""+EndOfLine
theShellCode = theShellCode+"file mytemptestfile.txt"+EndOfLine
My_Shell.Execute theShellCode
dim result As String = My_Shell.Result
'This should return a text string giving the input text's encoding
return Replace(result,"mytemptestfile.txt: ","")
End Function
I’ve tried screwing up the encoding. But the result doesn’t show my encoding:
dim theLeft as string = "ö ä ü ß"
for currentEncoding as integer = 0 to Encodings.Count - 1
dim EncodingInternetName as String = Encodings.Item(currentEncoding).internetName
if EncodingInternetName.IndexOf("iso") = -1 and EncodingInternetName.IndexOf("windows") = -1 then Continue
dim newString as string = DefineEncoding(theLeft, Encodings.Item(currentEncoding)) '<---convert
newString = ConvertEncoding(newString, Encodings.UTF8)
Result.Add(EncodingInternetName + " " + newString)
next
Okay, so that means that the text contains all valid unicode characters. At some point in the text’s history, before you received it, some software (email server?) attempted to read it and interpret it as unicode. If it contained any illegal codepoints, they must have been discarded, meaning that all remaining characters are valid unicode, even though they’ve been interpreted as the wrong characters.
As I see it, the only automatic way to figure out how it began its life, you’d have to go back to before the event where something tried to interpret it as unicode. And, that likely happened before your application received it.
The email came from a Windows email client to Mail. I read the email from the hard disk. Emails are split into the parts. Then I parse the data from the meta data like content transfer encoding. Only then the email parts are given their encoding. This usually works fine.
Here I need to figure out which encoding the data has. Then I need to fix the data. Figuring out how to fix the data in batch is the last task.
Ah! I think I found the Rosetta stone for your encoding.
“aufnahmebestätigung” is a word in German - don’t ask me what it means - and is very likely the correct word for the garbled “Aufnahme-Best…” near the end of the email. Perhaps that will give you enough to go on!
Edit: and upon further reading, it looks like you have already arrived at the same conclusion via a different route. Congrats!
I don’t have the raw data of the email. The content-type is multipart/alternative but there is no second part. The html has a charset of windows-1252. If there is no information in the content-type my email parser takes the information from the html. I would need to do some extensive analysis to change the behaviour.
Hmm, I suppose a missing charset means default to ASCII although I don’t know what th eabsolute latest RFC has to say about that. If you have the html you could try changing the charset to utf8 and see if that improves matters. I do find that Windows email clients tend to lie from time to time.
That is true. I do quite some checks to figure out if the data is okay. But my app does email in batch. Therefore, I need to figure out quickly what type of encoding the email part has. So far the code I posted above fixes most of the problems.