This is the result of the project using a comic book edited in France.
The data archive is (data generated with the project):
I place three screen shot at the end for better understanding.
The project takes around 3 seconds to process the data and display the resulting html in TextArea. This is the maximum size for a folder to be processed (to date).
Conditions of the run:
i5 laptop from 2014
around 36Mbps external hard disk *
macOS High Sierra
EyeTV software running (DVB TV)
Of course, connecting an SSD (without an USB 2 hub that slow down the data access time) will speed up the process.
Using an Apple m1 laptop with the master data stored in its fast internal SSD will also speed-up the process.
In the future, I will make an intensive search to accelerate the code process time.
I just used the project, the part that extract data from a master folder, from the IDE.
The folder holds 26.8GB of data stored in 452 folders (for a total of 18,808 items [files and folders])
To be able to understand here’s a simple explanation about what the project do:
From a dropped folder (master), the project…
Open each fist child of that master folder
Search an archive file and read its size
Search a folder that ends with a ‘-’ (no space before or after)
Read each file name in hat folder
and process it to make a book summary (check the provided archive contents)
Create two tables:
a. a table of the missing issues (with magenta background)
b. a table of the scanned issues (with alternate background clors: blue and yellow)
The method store the data as html in a TextArea.
The user have two choices (beside clearing the result):
a. Display the html data in another window that have an HTMLViewer
b. Save the html data (TextArea contents) into a… html file
I use two loops to alphabetize the items to be read from the hard disk;
I use two loops to scan the data folder; one to process each folder n the master foldr, the second one process the scanned files names to build the table of contents.
Each magazine scanned pages file names use a file name that holds the page number and a simple descrption of what’s in the scanned page or nothing; look at the resulting html to beter understand. You know what a Table of Contents is.
Nota: the project is able to resize and save the magazines covers from a folder into an “images” folder used by the generated html file.
Also:
If the project find a “Notes.txt” file, it load its contents (as html) and place its contents below the scan image (look at the archive).
- The hub I used (I get t wth the Apple m1 laptop) seems to be an old gat that slow down everything below 40 MBps (checked with a ad hoc software). Some vendor “good” work (!).
Data about each scan page resides in the file name. Below is page 1 for issue 451:
Mandrake 451 - 01 - Couverture par Mario Caria (Mandrake).jpg
The sorfware will report that as:
- Couverture par Mario Caria (Mandrake)
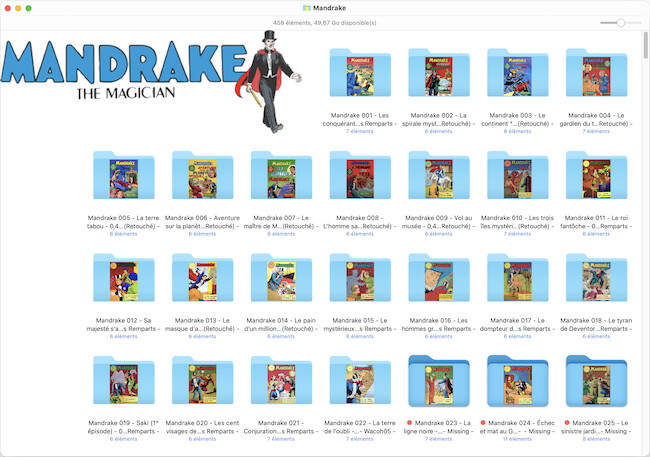
This is a part of the master folder. Each folder holds data about one issue (first 21 issues displayed).
Contents of issue 451; notice the archive and the default MacOS icon (whre the scans of the issue resides).

Isn’t my icon nice ?
