You could use the URLConnection class, connect to your website and make a GET/POST request with the necessary variables, then receive and parse the response.
Another way is to use an HTMLViewer and use Javascript to extract the information you need.
You could also shell to curl and retrieve your page that way (or use one of the MBS curl classes).
Here’s what I use, assuming you want to download a file:
Protected Function getURLConnectionFolderItem(URLConnectionHost As String, f As FolderItem, URLConnectionTimeOut As Integer = 10) As FolderItem
Var tempURLConnection As New URLConnection
Var MIMEType As String = "application/json"
Var HTTPStatusCode As Integer
If f = Nil Or URLConnectionHost = "" Or (URLConnectionHost.left(7) <> "http://" And URLConnectionHost.left(8) <> "https://") Then
Return Nil
End If
Try 'network timeout causes exception!
#If TargetWindows Or TargetLinux Then
tempURLConnection.AllowCertificateValidation = False 'Windows gets a Security Error if True
#EndIf
tempURLConnection.SendSync("GET", URLConnectionHost, f, URLConnectionTimeOut)
HTTPStatusCode = tempURLConnection.HTTPStatusCode
tempURLConnection.Disconnect
Catch Error
Return Nil
End Try
If f <> Nil And f.Exists Then 'And HTTPStatusCode = 0
Return f
Else
Return Nil
End If
End Function
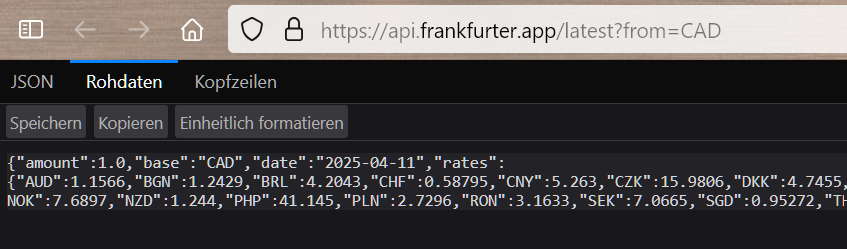
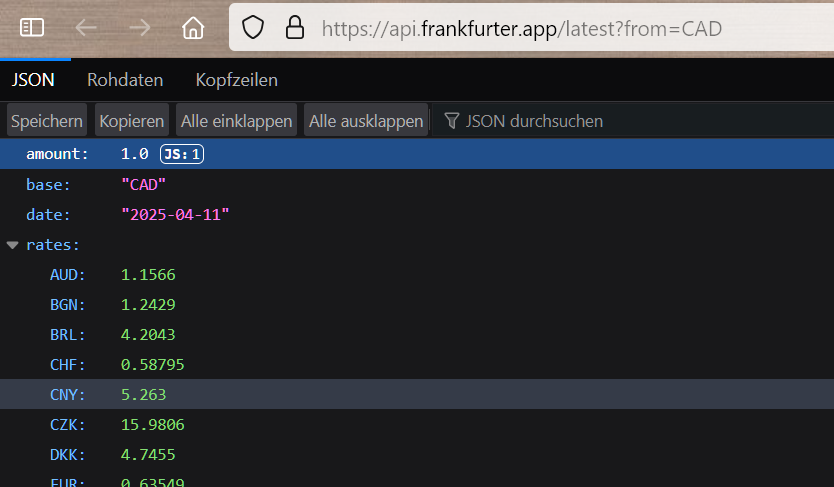
However, I don’t want to download a file. Let’s say I want to track the value of the Canadian dollar, and a banking website FREELY AND OPENLY (no bad stuff being done) posts it.
I want to get the value from the website, and plot it.
Yes, I am Canadian. And proud of it! But I just used that option as an example!
If it’s a banking website, they will certainly have and api you can use to get the information. Scraping a website (downloading it and picking out information) is generally frowned upon.
I used the Canadian Dollar example as it was the first thing that came to mind. I stay far away from touching things that I know… don’t like being touched.
Indeed it is, unless one wholeheartedly agrees with Camus’ famous dictum that “one must imagine Sisyphus happy”. The parsing part as such isn’t so bad but going this route puts one in a treadmill as every so often the website’s code changes and one has to catch up, fixing one’s broken parsing code.
Indeed, scraping and parsing is sometimes necessary.
Perfect example: I place hundreds of Amazon orders a year for my business. Amazon used to offer a tool that let you download your order history for a year in a CSV, I need this to file my taxes. They no longer offer this tool and scraping is the only way to get this data efficiently.
There are libraries dedicated strictly to scraping html, BeautifulSoup in Python is particularly versatile. Not sure if anyone has written generic classes to abstract the legwork in Xojo, but I have personally written a ton of html parsing code over the years. Chilkat’s HTMLToText and HTMLToXML have also been helpful at times.