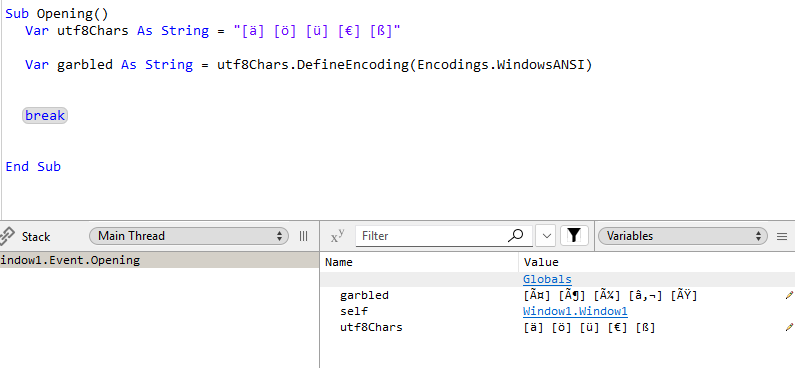
I have a problem fixing Windows1252 mojibake. I know how to fix mojibake - first do a convertencoding and then a defineencoding. I also have code to recognise different types of mojibake. I have one user where I can’t fix the mojibake and I’m not sure what is happening. I can’t even reproduce the issue myself. For me with the original data everything looks fine.
The original result:
1 x Bett Simple Hi 79 (ga.10708.11014) =3.906,00 EUR
Lieferzeit: 6-8 Wochen Amerikanischer Nussbaum: 180 x 200 cm Farbe: Holz natur geölt
SonderlÀnge/-gröÃe: SonderlÀnge 220 cm
Rahmenhöhe: Rahmenhöhe 32 cm2 x Lattenrost Physiophorm S (ga.10708.11156) =702,00 EUR Lieferzeit: 3-5 Wochen GröÃe: 90 x 220 cm
Trying to fix this by doing:
theString = theString.ConvertEncoding(Encodings.WindowsANSI)
theString = theString.DefineEncoding(Encodings.UTF8)
However, the result is (from a different email):
1 x Nachttisch Xanadu (ga.10708.11087) =617,00 EUR
Lieferzeit: 6-8 Wochen OberflËche: auf Farbton gebeizt und seidenglËnzend lackiert (standard)
Holz: Buche auf Kirsche gebeizt
Fu?: Alu-Fu?abschluss ---------------------------------------------------------------------- Zwischensumme:617,00 EUR
abzíglich Rabattgutschein - NEU-KUNDE: -25,00 EUR
abzíglich Online-Rabatt:-18,51 EUR
Lieferung per Spedition:30,00 EUR
inkl. 19% MwSt.:96,36 EUR
Endsumme:603,49 EUR
Does anyone have an idea what I’m doing wrong here?