The Text datatype was deprecated in Xojo 2021r1. Whilst Xojo do tend to support deprecated functions, etc for a long time I cannot bring myself to begin a brand new complex app to fruition using a deprecated class as it’s too risky. I’m therefore asking Xojo to consider un-deprecating the Text datatype and I want to explain why.
I’m writing a code editor which, as you can imagine, has to be accept arbitrary textural data from users including not only emojis but also textual characters from non-English languages. The String class (whilst much faster than Text) simply does not work when manipulating text that contains these characters and there are no good workarounds. I will give you two examples:
Example 1 - slicing characters:
Let’s say the user enters this text: "😀+☺️".
This is three visible characters.
Suppose the user presses the backspace key in my editor (i.e. they want to remove the second emoji). Xojo implies we can do this:
Var s As String = "😀+☺️"
s = s.Left(2) // Get the first two characters
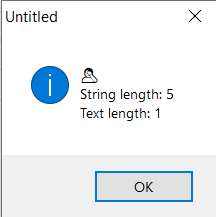
The trouble is this silently fails. Since the second emoji has a length of 2 (not 1) the returned string is broken. This is really nicely demonstrated in Xojo’s IDE (which also fails to handle non-English characters correctly):

Notice how pressing the delete key in the actual Xojo IDE breaks the string. I suspect Xojo Inc are using Strings under the hood for data storage so they are also seeing this bug.
Further manipulation of the s String returned will continue to lead to broken and unpredictable results. This behaviour affects all the String functions that manipulate the length of a string (Left, Middle, Right, etc).
Example 2 - getting the length of a string
How long is this piece of text:
Var s As String = "☺️"
// What is s.Length?
“Length is 1, right?” Wrong. In this case Length is 2. This is because this particular emoji is composed of two code points, not one. How about this emoji?
Var s As String = "😀"
// s.Length must be 2 right?
Nope, s.Length in this case is 1 (which is correct).
The “solution” to solving this dilemma using String is to iterate over all characters in the string using the String.Characters method and manually counting them:
Function CharacterCount(Extends s As String) As Integer
Var count As Integer = 0
For Each c As String In s.Characters
count = count + 1
Next c
Return count
End Function
Whilst this “solves” the problem of getting an incorrect length, it doesn’t fix the broken .Left, .Right and .Middle functions which will break because they also work on code points and not characters.
API 2.0 really confuses things here
The Text datatype solves all of these issues (that’s why it was created in the first place!) but it has now been deprecated. Xojo keep saying to make feature requests to add new functionality to the String datatype to handle things that Text used to. The trouble is Xojo have made odd choices with renaming methods on the String datatype in API 2.0 which confuse the issue. For example, Xojo renamed String.Mid to String.Middle but didn’t change the functionality. What would have been sensible would be to have String.Middle act like the old Text.Mid function that actually correctly returned the middle characters for multi-codepoint strings.
I know people will complain that Text is slow (and it is) but there is a real use case for it to not be deprecated. I am now facing the prospect of rewriting my entire code editor (a multi thousand line project) to use Text rather than String because I was duped into thinking that String had been updated to correctly handle these characters (the docs have subsequently been updated). I will have to accept that Text is slower than String (hopefully the editor will still be usable).
Can I get some support for this?
I would be really interested to hear from @Geoff_Perlman about the reasoning behind the Text datatype and why it could not be “un-deprecated”.