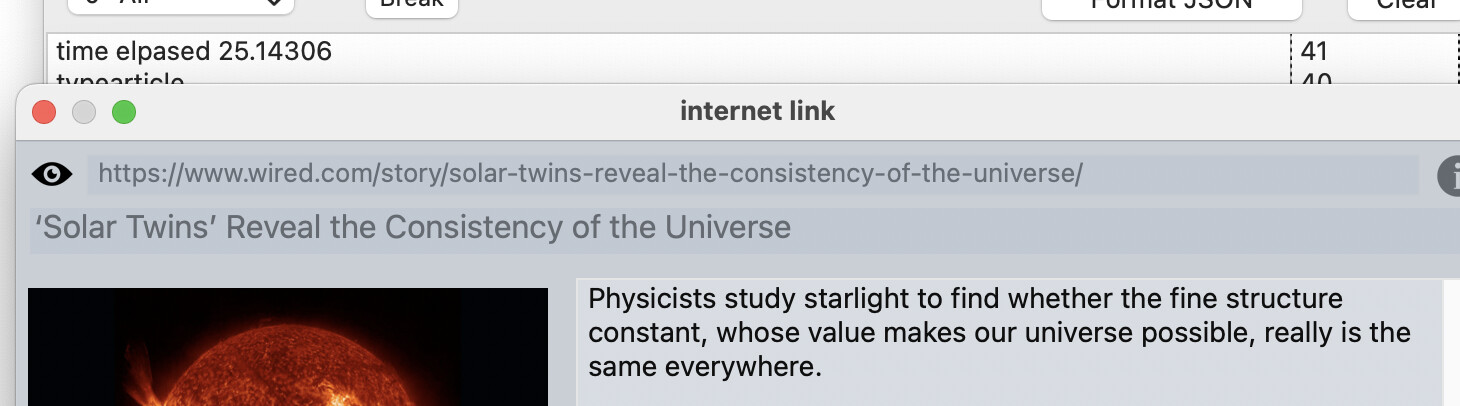
Instead of splitting the HTML and reading each line (the HTML could actually be a single line) is there a Regex I can use to extract the “content” tag of each property: “og:type”, “og:title”, “og:image” and “og:description”?
From your example html, you’d like to return something like the following?
og:type, product
og:title, Product Title
og:image, https://www.example.com
og:description, product description
To do this, I used some text routines that I’ve created to help me rebuild my old website from the saved html. They don’t use regex, because I’ve never been good at regex. The above example took me a couple of minutes to code with my text routines. If you’re interested, I can post it. But be warned, it is not a true html parser. It works fine parsing machine generated html, but if the pages were human created, there are occasionally spaces stuck in inconvenient places that may cause problems. The tools address some of these issues, but may not catch all of them.
Yes that’s exactly it.
I would be interested in seeing your parser and compare the speed against the regex I’m using. On large pages it takes up to 200ms to get the opengraph tags.
While acceptable, I’m trying to optimize my web app as much as possible. There can be up to 300 concurrent sessions.
If you’re already using regex, then I’m sure it will be considerably faster than my code, but the code is below. I’ve also made a small project file that includes a couple of other text manipulation routines.
Public Function ExtractOG(rawHTML As String) as string
dim cleanHTML As String = CompressWhitespace(rawHTML)
dim head() As String = parseTxtToAry(cleanHTML,"<head>","</head>")
dim output as String = ""
if head.Ubound>=0 then
dim meta() As String = parseTxtToAry(head(0),"<meta",">")
if meta.Ubound>=0 then
'At least one meta tag has been found
for i as Integer = 0 to meta.Ubound
output = output + parseTxt(meta(i),"property=""","""")+", "+parseTxt(meta(i),"content=""","""")+EndOfLine
next
end if
else
'This only happens if the head can't be found
end if
return output
End Function
Public Function CompressWhitespace(s1 As String) as String
'Removes duplicate whitespace characters from text.
'Also trims leading and trailing whitespace.
'This is not very efficient code, and should be
'replaced with more efficient RegEx code.
dim s As String =s1
'Convert all whitespace characters into spaces
s=ReplaceAll(s,chr(9)," ")
s=ReplaceAll(s,chr(10)," ")
s=ReplaceAll(s,chr(13)," ")
dim L As Integer = len(s)+1
'Replace duplicate spaces with single spaces repeatedly until length stops changing
While len(s)<>L
L=len(s)
s=ReplaceAll(s," "," ")
'These are specific to html
s=ReplaceAll(s,"< ","<")
s=ReplaceAll(s," >",">")
wend
return trim(s)
End Function
Public Function parseTxt(s As String, delimA As String, delimB As String) as string
'Returns a string array (or EOL delimited string) of every substring of s,
'that falls between left delimiter text delimA and right delimiter text delimB.
dim outList() As String = Split(s,delimA)
dim hitCount As Integer = UBound(outList)
if hitCount>-1 then outList.Remove(0)
hitCount=hitCount-1
for i as integer = 0 to hitCount
dim ss() As String = split(outList(i),delimB)
if UBound(ss)<0 then
outList(i)=""
else
outList(i)=ss(0)
end if
next
'Choose one of the following return options
return Join(outList,EndOfLine)
'return outList
End Function
Public Function parseTxtToAry(s As String, delimA As String, delimB As String) as string()
'Returns a string array (or EOL delimited string) of every substring of s,
'that falls between left delimiter text delimA and right delimiter text delimB.
dim outList() As String = Split(s,delimA)
dim hitCount As Integer = UBound(outList)
if hitCount>-1 then outList.Remove(0)
hitCount=hitCount-1
for i as integer = 0 to hitCount
dim ss() As String = split(outList(i),delimB)
if UBound(ss)<0 then
outList(i)=""
else
outList(i)=ss(0)
end if
next
'Choose one of the following return options
'return Join(outList,EndOfLine)
return outList
End Function
well your code seem to do more stuff, and mine is not bulletproof
one question, why do you remove whitespaces :
dim cleanHTML As String = CompressWhitespace(rawHTML)
if usefull can i steal your code ?
Thanks @DerkJ, I was using OpenGraph but it was a bit too slow in my tests.
Though I still use it for Amazon URLs because Amazon does not support OpenGraph tags.
But the Regex pattern in the stackoverflow link seems to be perfect for my needs.
!! great, i guess i know now why i need to learn regex , thanks !
when i have some time, iwill do a method i’ll post somewhere, there is more metatags than that, i’ll try to figure out hoàw to add those tags, and there is a keyword list, dunno if this doable using this
you mind sharing more explicit code ? i’m sure there there’s many lwho would benefit from it, i wanted to do so but my code is dirty
Sure, here is my code to extract the OpenGraph title and image url
Dim title as String
Dim imgURL as String
Dim reg As RegEx
Dim myMatch as RegExMatch
if page.Contains("og:") then //page is a String containing the HTML webpage
Dim patterns() as String
patterns.Add "<meta\s[^>]*property=[\""'](og:title)[\""']\s[^>]*content=[\""']([^'^\""]+?)[\""'][^>]*>"
patterns.Add "<meta\s[^>]*property=[\""'](og:image)[\""']\s[^>]*content=[\""']([^'^\""]+?)[\""'][^>]*>"
patterns.Add "<meta\s[^>]*property=[\""'](og:image:url)[\""']\s[^>]*content=[\""']([^'^\""]+?)[\""'][^>]*>"
//Feel free to add more patterns matching twitter:title, twitter:image if necessary
for each pattern in patterns
reg = new RegEx
reg.SearchPattern = pattern
reg.Options.Greedy = False
myMatch = reg.Search(page)
if myMatch <> nil then
if myMatch.SubExpressionCount > 2 then
Dim og_type As String = myMatch.SubExpressionString(1)
Dim og_content As String = myMatch.SubExpressionString(2)
Select case og_type
Case "og:title"
title = og_content
Case "og:image"
imgURL = og_content
Case "og:image:url"
imgURL = og_content
End Select
if title.IsEmpty = False and imgURL.IsEmpty = False then
Exit
end if
end if
end if
next
End if
//Now do whatever with the title and imageURL
so yesterday morning, i gave me an advent challenge to make your 3 lines works and learn regex the fastest i can.
i read the xojo doc, tried some didn’t undersatand well the doc about regexmatch
so i switch to mbs and i made parsing in no time !!
then i realised its not web
redid using xojo, there is no goodsearch example in te doc, so i tried by mistakes
i created a file to test,
i would have add more tags other than og: but i’m too busy wit not related xojo stuff, will update this file later