Hey guys,
Background:
I want to parse xojo_code files for a future open source project. There is a tool called “JQAssistant” were we want to write a plugin for. Basically, it helps to visualize your code, making it for example more easy to identify unused code in our XOJO project. Ultimately, we will:
- learn a lot by taking this effort
- have a little side project working as a team
- give others a tool in their hands to do the same
As a result, I would really like to get XOJO into some visualisation like this (source):
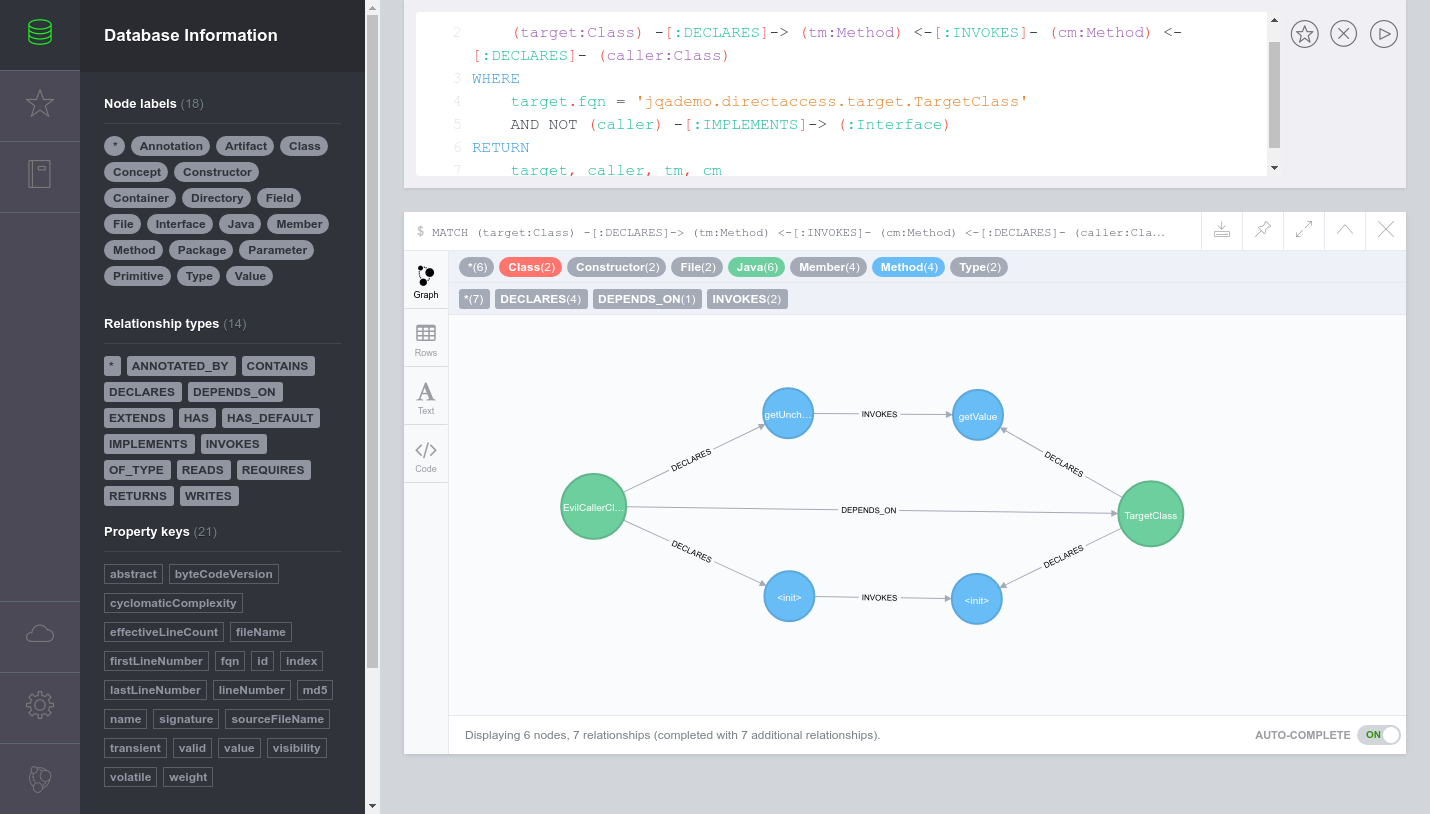
JQAssistant saves it’s data in a graph database called Neo4J. This software comes with the visualization above (it’s like an interactive query-result web frontend editor to issue queries.)
We could then query a Neo4J database with Cypher - in it - there would be all of our programs information so that we are able to validate coding styles, see unused code, etc.
Our ingredients for making this happen are:
- a XOJO Parser which helps us creating an AST (I will use a parser generator like ANTLR)
- An AST “interpreter” which is basically the core of the JQAssistant plugin
To the main question:
To be able to parse XOJO files, I would really appreciate a “formal language definition” or grammar for XOJO (e.g. like the JSONs grammar)
Can anybody point this out to me, so that our project becomes easier?
XOJO also won’t loose intellectual property, because the grammar is visible widely in multiple github projects so that people could deduct the grammar if they really want to.
I guess I would be able to reverse engineer it by myself, but this would slow the project down massively.
Thanks a lot for your help!