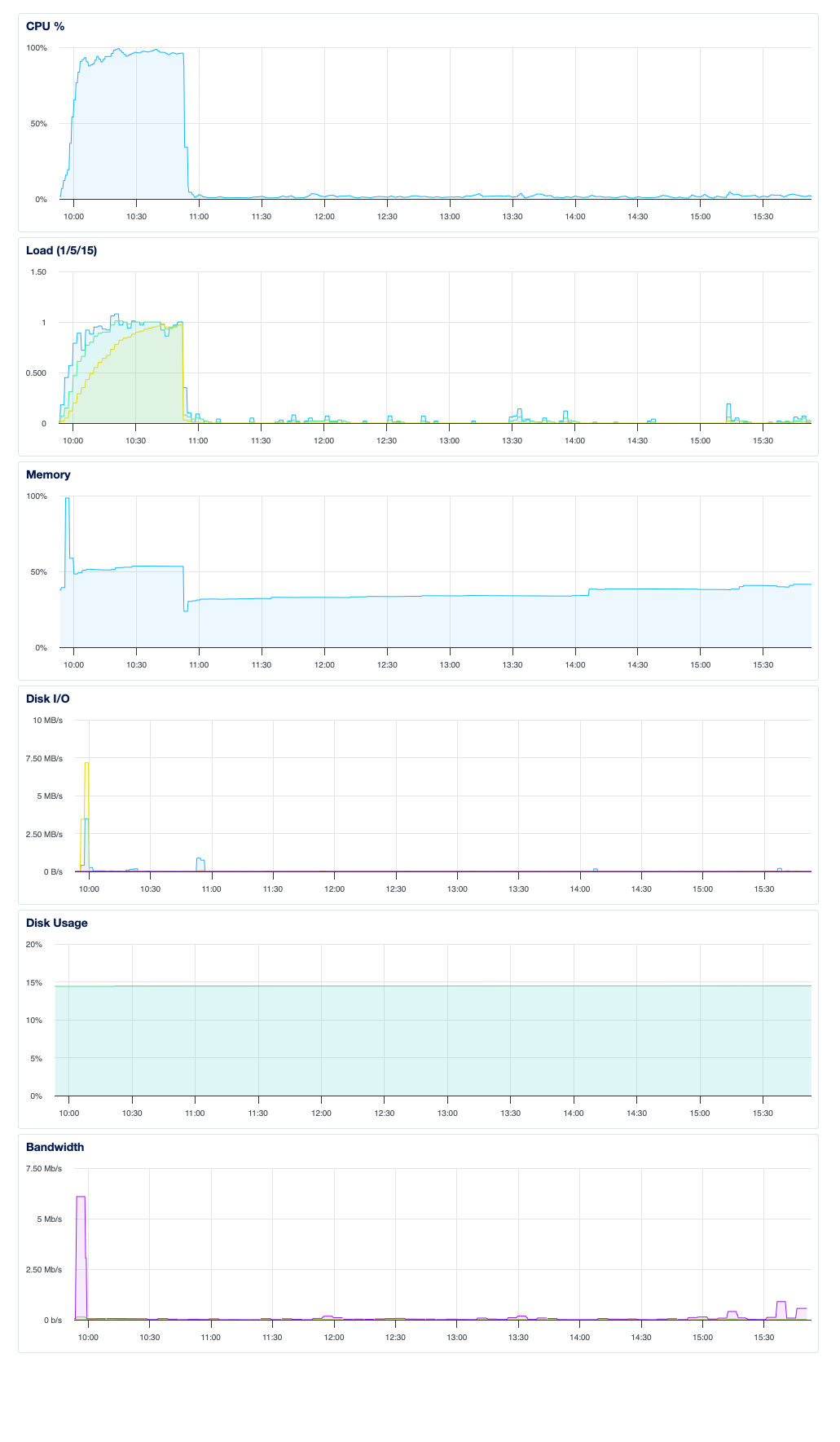
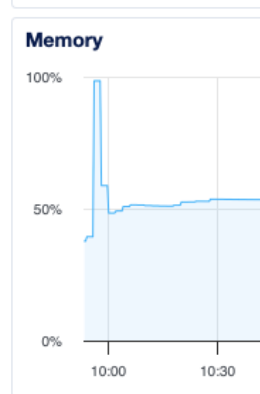
I was in a hurry to fix the issue so I restarted the server without connecting to it and checking which process was using all CPU.
Next time this happens, I plan on connecting to the server and running htop command.
Would you have any other recommendation on what to do next time it happens?
@Jeremie_L , I used to see this kind of behavior before I required Lifeboat install a swapfile. I haven’t seen it on my instances since. This makes me fear some kind of regression in the framework, what version of Xojo did you use?
FWIW, Amazon EC2 instances can be watched by a service called CloudWatch that will reboot the instance automatically if it gets stuck at 100% CPU like this. It was an unfortunate solution I had in place until the swapfile fixed the issue.
Do your nginx logs show some kind of heavily increased traffic in that time? I can help you with this privately if you need.
Long ago a staff member said that adjusting these values is almost never necessary, so Lifeboat leaves the default values.
I prefer staying on digitalocean as the MySQL database is stored in the same region as the instance running the web app. And I would need to reconfigure all my apps if I changed hosting service.
A NilObjectException wasn’t handled and the stack trace is very limited:
NilObjectException: - ErrorNumber: 0
, in _HTTPServer.HTTPRequestEngine.ThreadFinished%%o<_HTTPServer.HTTPRequestEngine>o<_HTTPServer.HTTPRequestContext>
, in _HTTPServer.HTTPRequestThread.Event_Run%%o<_HTTPServer.HTTPRequestThread>