My app has a function that changes the case of a string to Title Case (every word begins with a capital letter). It has a user-configurable stop list that contains words whose case is not to be changed (e.g. DNA). I use regex to search for the presence of such words in the string and ensure that they appear as in the stop list. A user has reported an edge case where mistakes can occur when a word as accented Unicode characters. I can see where the problem lies, but I can’t come up with a solution. I’m using a search pattern that I’m pretty sure @Kem_Tekinay helped me with:
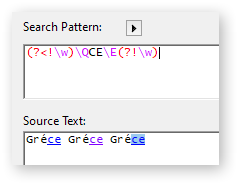
(?<!\w)\Q" + stopWord + "\E(?!\w)
The intent is that only whole words will be found, and the characters between \Q and \E (the stop word) are treated as literals. The problem is that \w only deals with ASCII values. This is a real life example that fails:
stopWord = CE
string = Gréce
The search identifies the “ce” after the é as a match, and the output becomes
GréCE
If the é is changed to e the output is correct (Grece).
Suggestions on how to deal with such examples are appreciated.
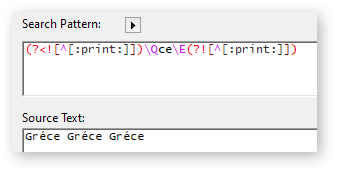
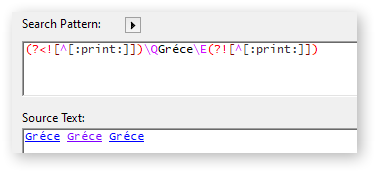
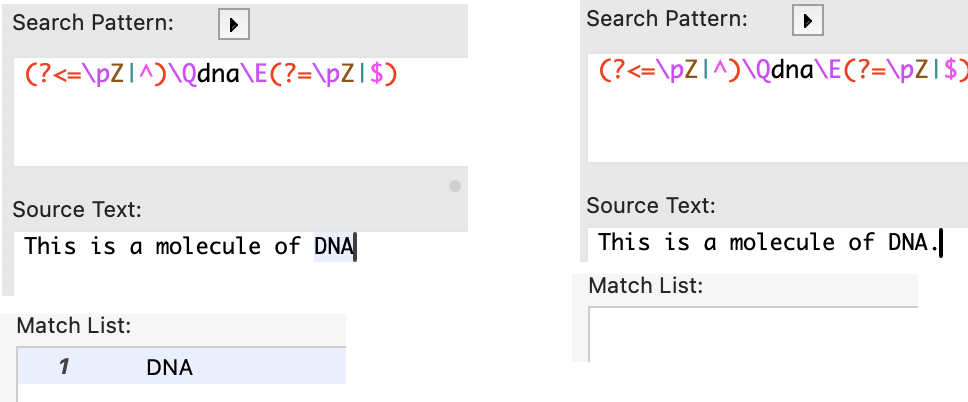
@Kem_Tekinay Thank you, Kem, this is very close. It correctly recognizes that an accented character should not be interpreted as end of word. But it fails to find a match when the word is followed by punctuation.
For example, “dna” is found if it is freestanding, but not if it is followed by punctuation.
In RegExRX, under the pop-up menu next to Search Pattern, you will find all kinds of tokens. Under “Unicode Scripts & Properties” you will find the symbols you can use with \p or \P along with their explanations.
I had actually explored that menu, but you have to somewhat know what the answer is going to be understand and apply the information. I did a lot of googling before posting, and answers to similar questions were all over the place, many restricting matches to Unicode character ranges and such. I figured there must be a more elegant solution (searches that take into account accented characters seem pretty basic, especially outside the US). Thanks for providing it.