I have data stored inside the file names of certain files. In these data, I have dates in the French format: janvier, février, mars, avril, mai, juin, juillet, août, septembre, octobre, novembre and décembre.
Have-you seen the diacritics ? I cannot extract the date to an object when the name of the month is février, août or décembre whatever test I think at… if month = “février” fails.
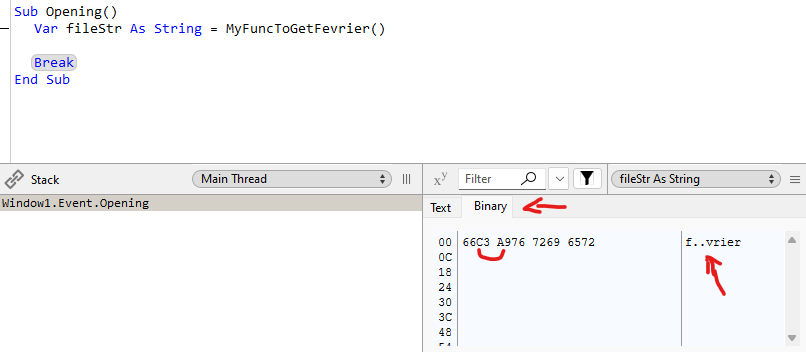
I don’t remember the correct names but sometimes you see é and is not the same as other é. One is a single character and the other is a combination of e and '.
My guess is that this is happening to you. But you need to give more information than “fails”.
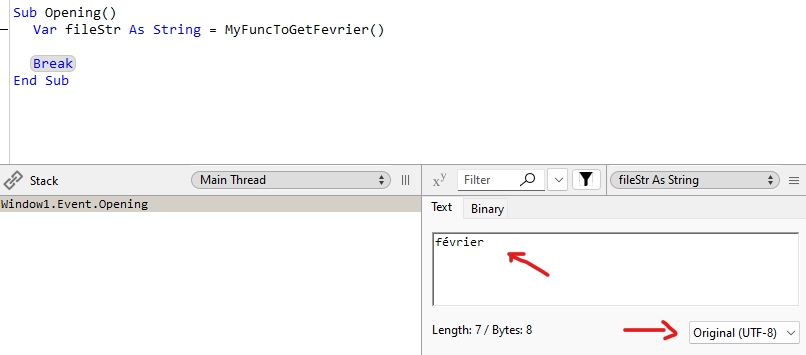
Also, it may be a problem of string encoding from your data. Can you check what the encoding is and the Hex for “février” just before you do the if (compare that with a test string = “février”)
The terms are “composed” and “decomposed” - essentially, a composed character in Unicode means that a single character represents the è, while in a decomposed situation the è is stored as an e plus the `.
They should compare to equal when using the standard string functions, though. Don’t compare the hex values - they will indeed differ between composed and decomposed strings.
These month names are typed from the Finder (macOS).
From a user point of view, nothing fancy, but… and other text is taken as is, so it is displayed correctly.
What do I mean by fail ?
When I use: If month = "février" then mn = 2
mn is never set. The compare does not works, just like if I ask: If month = "f|vrier" then mn = 2
Sorry. I do not know how to be more precise on the matter.
I short, I cannot convert a Date String “24 février 2024” to a Date Object 2024-02-24" because of the diacritic; no trouble for the other 9 months names.
Obtain such string from the system in a sample of code, store the name you get in a string var like fileStr, break, and inspect the filestr, Binary tab. What encoding it is showing? UTF, Nil, other? What are the HEX codes there?
Someone (here on the forum) gave me the solution some times ago and I wrote a Method:
Public Function NrmStgEnc(Extends CeTexte as String, CeForm as UInt32 = -128) As String
Dim TpEncod as TextEncoding ' Cette Method normalise l'encodage d'une String. Un "é" (1 digit) peut aussi être encodé "´e" (2 digits)
If not(CeTexte = "") Then ' Depuis Catalina il y a des problème avec les encodages des accents. Un fichier nommé "Téiök" risque de retourner faux au test : (Fich.Name = "Téiök")
TpEncod = CeTexte.Encoding
If not(TpEncod = Nil) Then ' Par contre il n'y a pas de problème quand je fais .Child(Fich.Name) donc dans ce cas je ne normalise pas l'encodage
#IF TargetMacOS Then ' https://forum.xojo.com/t/accentuated-characters-in-name-of-folderitem-catalina/53892/18
If CeForm = -128 Then CeForm = 2 ' Sous Mac il faut utiliser 2
Declare Function CFStringCreateMutableCopy Lib "Foundation" (alloc as Ptr, maxLength as UInt32, TheString as CFStringRef) as CFStringRef
Declare Sub CFStringNormalize Lib "Foundation" (TheString as CFStringRef, TheForm as UInt32)
Dim mutableStringRef as CFStringRef = CFStringCreateMutableCopy(Nil, 0, CeTexte) ' Inutile : CeTexte.ConvertEncoding(Encodings.UTF8))
CFStringNormalize(mutableStringRef, CeForm)
' CFStringNormalize mutableStringRef, 2 ' Dans un exemple c'était 2, dans l'autre il passait CeForm en paramètre
CeTexte = mutableStringRef
' Avant je mettais l'un des encodages ci-dessous et ça corrigeait le problème (j'avais réactivé la ligne pour test)
' CeTexte = CeTexte.ConvertEncoding(Encodings.UTF32LE) ' Encodings.UTF32BE ' Encodings.UTF16BE ' Encodings.UTF16LE ' Encodings.MacRoman
' En mettant un des encodages ci-dessous ça ne corrigeait pas le problème
' CeTexte = CeTexte.ConvertEncoding(Encodings.UTF32) ' Encodings.UTF8 ' Encodings.UTF16
CeTexte = CeTexte.ConvertEncoding(TpEncod) ' return "" if there was an error , je pourrais le mettre en DefAppEncod
#ElseIf TargetWindows Then ' https://forum.xojo.com/t/special-character-folder-item-child-encoding/68751/35
#If False Then ' Ca ne marche pas, ça me fait merder GetFitemAbsPath
If CeForm = -128 Then CeForm = 1 ' Sous Windows il faut utiliser 1
Declare Function NormalizeString Lib "Normaliz.dll" Alias "NormalizeString" ( NormForm as Int32, lpSrcString as WString, cwSrcLength as Int32, pDstString as Ptr, cwDstLength as Int32 ) as Int32
Dim StringLength as Int32 = NormalizeString(CeForm, CeTexte, CeTexte.Length, Nil, 0)
Dim NormalisedString as New MemoryBlock(StringLength) ' see https://docs.microsoft.com/en-us/windows/win32/api/winnls/ne-winnls-norm_form for values for NormForm
Dim TampNbre as Int32 = NormalizeString(CeForm, CeTexte, CeTexte.Length, NormalisedString, StringLength)
If TampNbre > 0 Then
CeTexte = NormalisedString.WString(0).ConvertEncoding(TpEncod) ' return with the encoding the same as we received it
Else
CeTexte = CType("", String).ConvertEncoding(TpEncod) ' return "" if there was an error , je pourrais le mettre en DefAppEncod
End If
#EndIf
#EndIf
End If
End If
Return CeTexte
End Function
Then you do: MyStringWithNormEncod = MyStringWithoutNormEncod.NrmStgEnc
I didn’t test if finaly MyStringWithNormEncod contains only é on 1 digit or on 2 digits, but if you do that to all your string they will encode the é è à ç the same way.