I am creating a text file (tab or comma delimited) on the Mac platform that opens in a spreadsheet application.
I’m creating the contents of the file by using:
text = text + NewCharacter
I am allowing the user of the application to specify the termination characters of each “spreadsheet line” as a preference in the application. Two characters are available to specify.
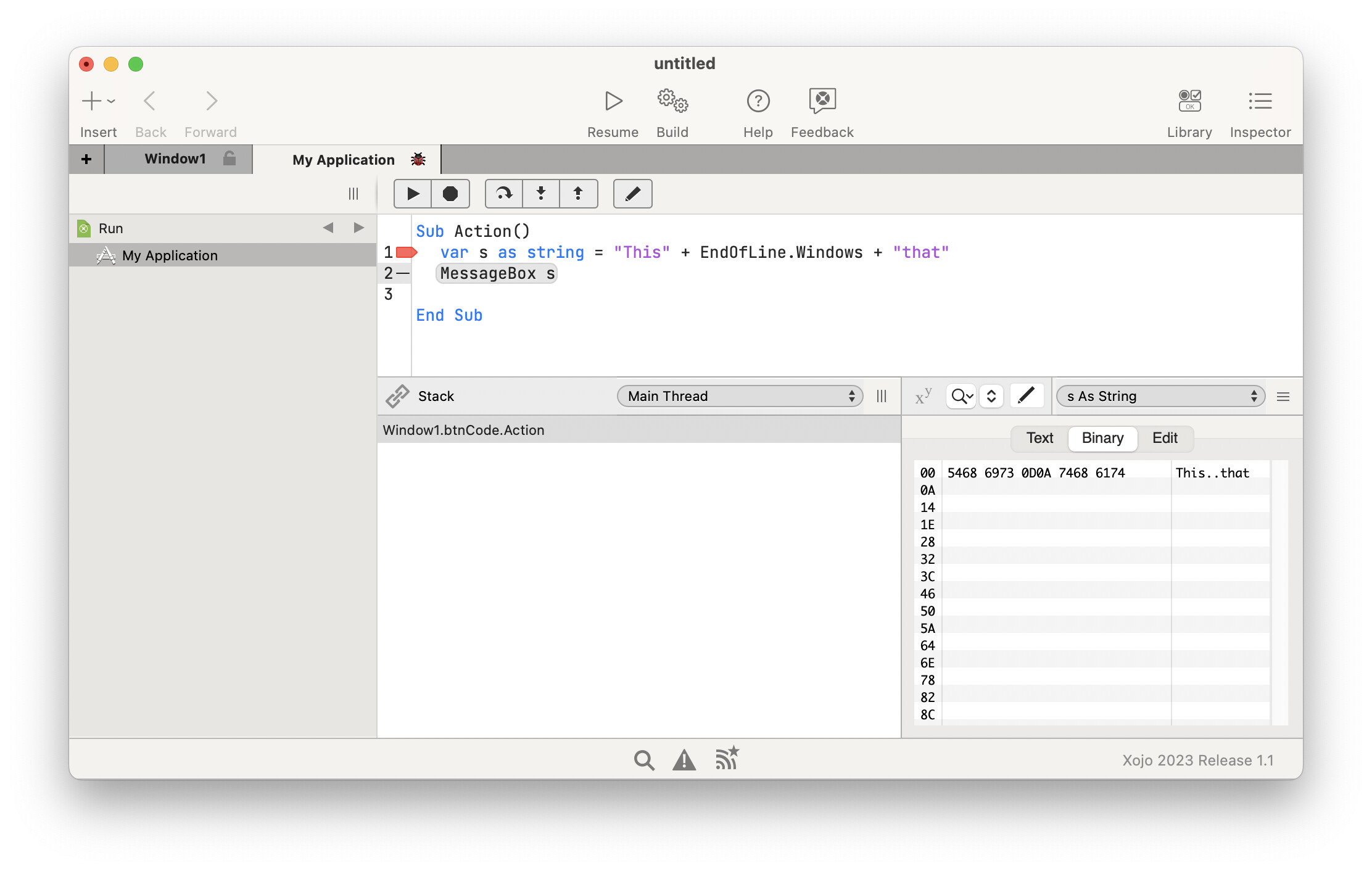
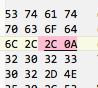
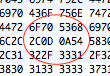
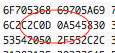
If the user specifies a LF (&h0A) then a CR (&h0D), in that order, the application works perfectly. I verify this with a hex dump in BBEdit and TextMate. However, if the user specifies a CR first, then the LF, the hex dump shows NO CR in the file, only the LF.
After spending a considerable amount of time trying many different troubleshooting ideas, I did find that if I hardcoded an ascii “space” character (actually any character would work) between the CR and LF, then the CR would suddenly reappeared in the file.
Im using Xojo 2013 r3.3 due to the need for Mac OSX 10.6 compatibility.
I’m reading a TAB delimited text file, column by column, that is formatted like a spreadsheet.
I’m inserting the customer specified field delimiter between the data columns.
Then, at the end of the line, I’m adding the two characters for the line terminator.
This is inside a bigger loop that reads each line of the input file.
When the bigger loop is complete, the Segment variable will contain the entire file contents.
When examining the Segment variable (before ever saving the variable to a file) I can see the problem.
The problem occurs when EDI_LT = CR and EDI_LT2 = LF . The CR data disappears from the variable. If EDI_LT = LF and EDI_LT2 = CR, the data in the variable is correct.
Element, Segment and DataValue are string variables.
Cell = 0
Do
// Point to the current column from the input file
Cell=Cell+1
// clean the data
DataValue=Trim(nthfield(rowFromFile(CurrentMapLine),TAB,Cell))
// Add the data and Element Separator (field delimiter) to the element
// The Element Separator is specified by the user (i.e. a TAB, Comma, etc)
Element=Element + DataValue+Chr(EDI_ES)
loop Until Cell > LastCell
// LINE COMPLETE - Add the Line Terminator
Segment=Segment + Element + Chr(EDI_LT) + Chr(EDI_LT2)
Thanks Emile for the link. I was not aware. I could have used this in several other projects I have written. However, what I am doing in this situation is creating an EDI (Electronic Data Interchange) file that will be uploaded to a manufacturer. Manufacturers that use the EDI interface don’t generally specify a “Windows”, “Linux”, “Mac”, etc. file format. Most specify their required file format down to the character level.
Hey Kem,
Yes, I’m viewing the string in BBEdit and TextMate and see the same result. And yes, feel free to send any tips my way. Although I started with RealBasic 1.0, I don’t program for a living. I just use Xojo as my “hammer” when my life is full of nails.
Those apps might be adjusting the EOL characters for you. You need to set a breakpoint where Segment is set, then use the debugger to examine the contents of the variable. The debugger will let you see the bytes behind the string, and I’ll bet you’ll see the contents are exactly what you expect.
The problem here is what defines a proper “line ending” varies by OS. My usual way to handle this is to map all line endings in a string to the current OS’s standard line ending. Xojo makes this real easy:
segment = segment.ReplaceLineEndings(EndOfLine)
Just add that line of code after you first populate your segment variable, and it will adjust whatever line endings it finds to the current platform’s standard.
Edit: And if you always want a specific line ending, regardless of the platform on which you are running, just add that qualifier as in:
Hey Kem,
That’s exactly what I’m doing, sort of. Since you can’t see the control character (CR/LF) in the debugger variable, I have to copy the contents of the variable and then paste it into BBEdit. At that point I do a hex dump to view the actual hex. At first, I was thinking the exact thing - that the app was changing the contents. However, when it did exactly the same thing in the second app, I’m not so sure now. Too bad you can’t view the hex value of a string directly in the debugger.
Thanks Douglas for the suggestion. I’m going to use this on two other projects I currently have in work. However, what I am doing in this situation is creating an EDI (Electronic Data Interchange) file that will be uploaded to a manufacturer’s server. Manufacturers, that use the EDI interface, don’t generally specify a “Windows”, “Linux”, “Mac”, etc. file format to upload. Most specify their required EDI file format down to the character level. And, of course, there is nothing standard when using the “EDI Standard”.
But all you need to do is look in the Xojo EndOfLines docs which I linked and choose the format which has the desired character sequence. Just because the manufacturer’s docs don’t call it by the same name, you can still select Xojo’s name for the requested format. That was all I was saying.
Sometimes you WANT line endings to conform to the current platform; sometimes you need to conform to a specific format. Xojo makes it super simple to do either.
Except that those are not the exact same string. The BBEdit version is missing the the x0D character, which implies BBEdit it changing the data as it loads it. Better to use a hex viewer utility when examining file contents (such as Hex Fiend) or in Xojo debugger to examine a breakpoint variable in Binary mode.
Thanks Douglas! Hex Fiend is downloaded and WORKS! Yes, that is what I was trying to show above. BBEdit has apparently been my problem all along. BBEdit blanks a CR ONLY if it is in front of a LF. All other sequences, BBEdit will show the CR.
@Grant_Pittard, am I understanding correctly that you are basically replacing all TABs in the file you’re reading with a custom character, and all the line endings with CR+LF? If so, wouldn’t it be easier to read the whole file into a string and then do something like this?
Hi Roger,
I only wish it were that simple. What I’m doing is taking data from a Point of Sale system and formatting it into an “EDI Standard” file format. All the data has to be cleaned, converted, cropped, rearranged and then assembled before saving and transmitting the EDI file. Because every manufacturer uses a different “EDI Standard” (lol) I have to make my code extremely flexible.