So I’m looking for a way of identifying a decent character to repent the font in a preview. FontBook for example shows “Alef” character for Hebrew fonts, Arabic fonts use “ain”, chinese 漢, Kannada script ಕ etc.
The obvious question, given a font how are they getting from that to the correct character set and then the correct character. I can’t use a plugin but I’m happy with Declares. I’m aware I can get from an NSFont. It appears to have an ability to provide a coveredCharacterSet, but then what?
We do something similar in our app but use the word Sample translated into different languages.
We do this by testing for the existence of glyphs in different Unicode script ranges so we know which writing systems are supported. Using that data we then apply some rules which then allows us to choose the correct sample text.
Unfortunately, I cannot share any code but you might be able to use MBS to do something similar.
I see were you are heading but I’m not sure it is a particularly easy direction. Given there are likely lots of different language variations available. Just looking through Font Book on my Mac I can see at least a couple of dozen possibly more.
I will see if I can find a definitive list of the different scripts out there. That at least would provide be with a scope for following this path.
Useful though. Thanks
So there is a concept in Unicode of a “Representative Glyph”, which I suspect is the answer to what Font Book is doing. Something to look into…
So I’m making progress with this. Basically, as Kevin suggested I’m looking at the Characters reported by the font and detecting language support. The hardest thing is finding the best code too. Represent a given language, I’m using Font Book’s label for the font as a guide.
I’ve discovered that many fonts support multiple character ranges. Lots of East Asian fonts support Chinese, Japanese and Korean. I’m constructing a string of all supported sets. Allowing the user to see the choices offered by the font. I will discuss fallback support in the help system.
What I haven’t got figured out is how to retrieve the first few characters within a Symbol font. There doesn’t seem to be a method for asking for it.
OK, I’ve pretty much got this sorted. It has been an interesting exercise. I’ve one final problem to resolve before it is worth posting some code here. That issue is fonts that lie. When asked if they support a certain character they claim to do so, however, if you attempt to use that character you end up with no glyph for the given character. I’m on track of a solution to that issue and will continue to work on it.
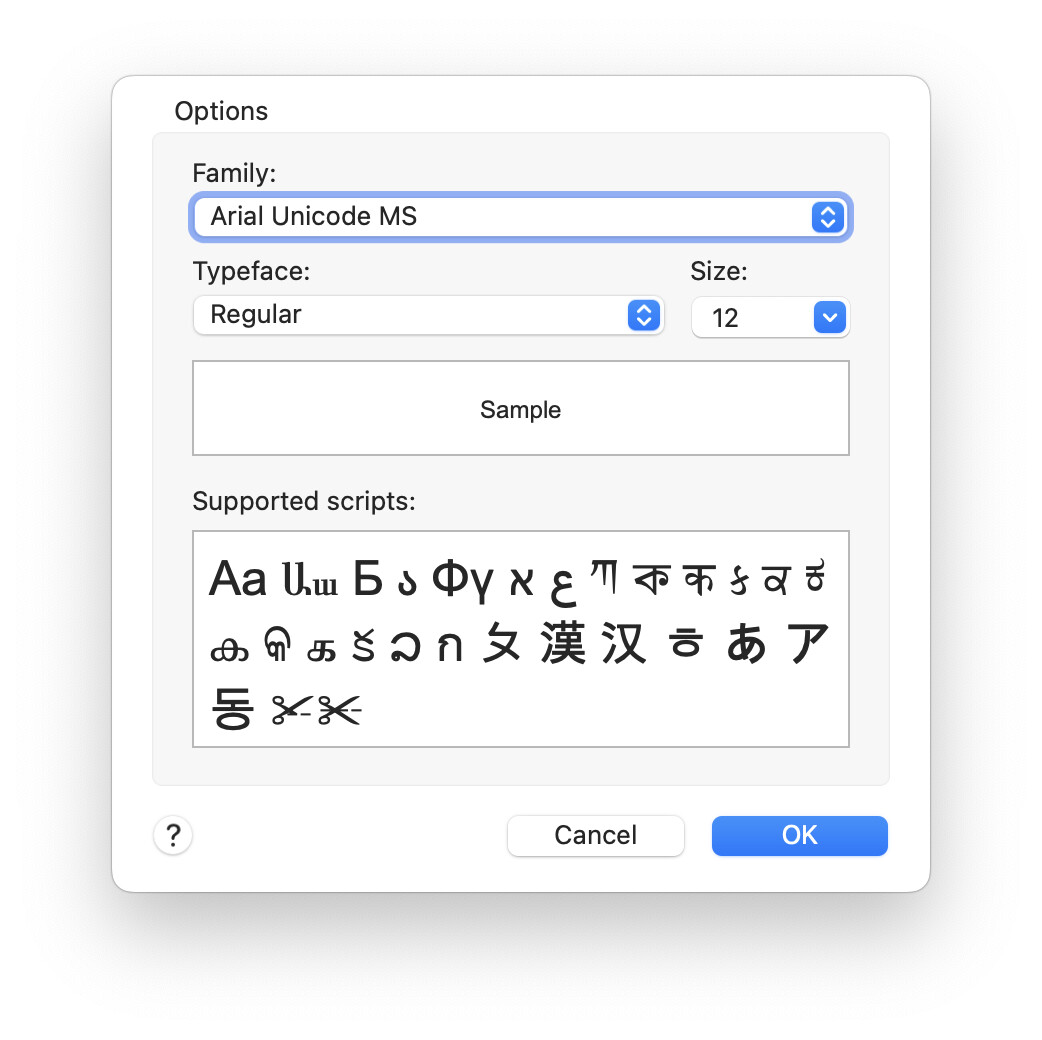
Currently my Font selector dialog looks like this:
The upper half, obviously, allows you to choose a font family and typeface and size to use within the application. The lower half show two separate previews of the font. The first shows a translatable string, which for English shows “Sample”. The lower preview shows the scripts supported by the chosen font. This is always shown in size 24, allowing the style and letter choices to be seen better.
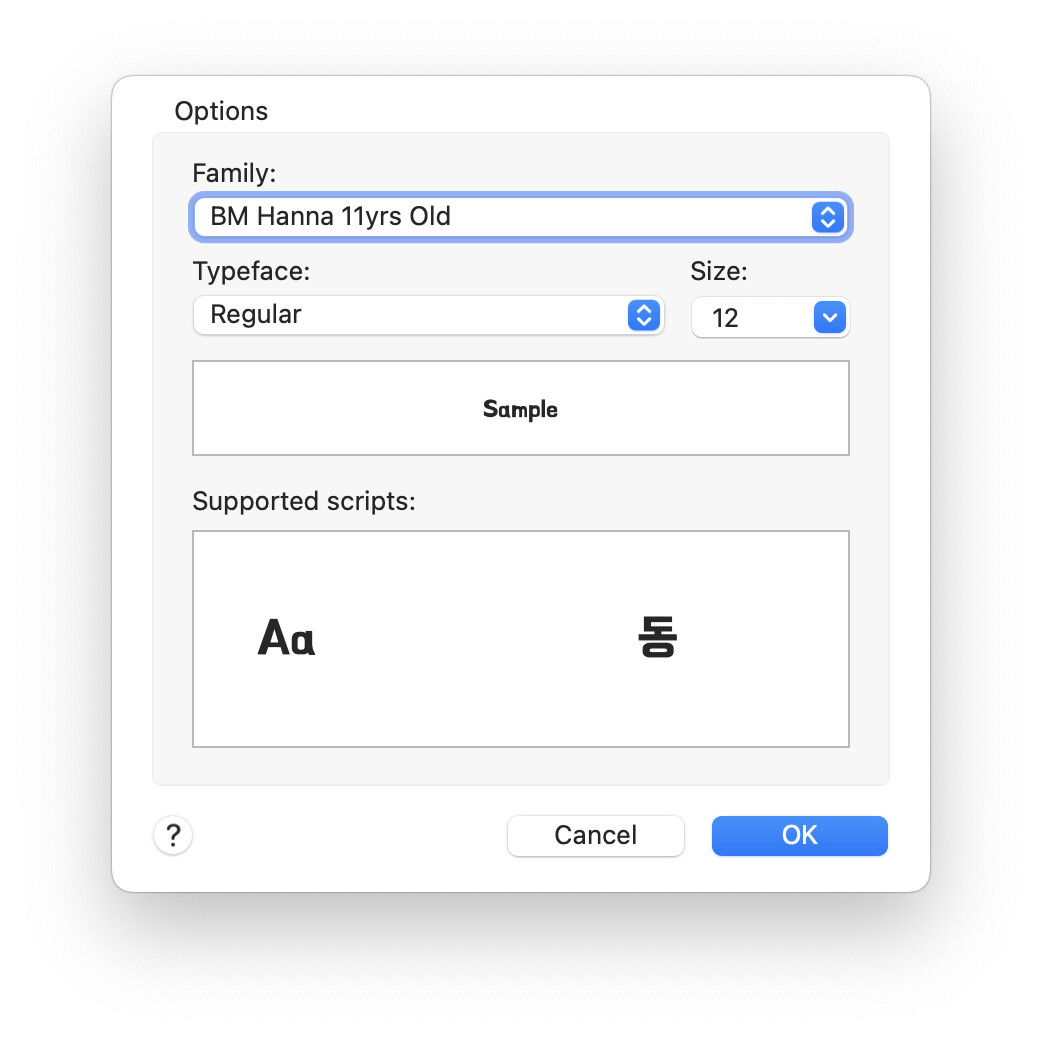
Here is an example of a font that lies about its supported scripts:
So my first attempt has fallen down. The plan was to use “CTFontGetGlyphsForCharacters” to retrieve the Glyphs for the code points I’m interested in, however, the font is actually returning Glyphs for the missing characters. The Glyphs are all even all different. They just don’t display anything when rendered. I’m pretty sure that leaves me rendering the character and seeing it it is blank, unless anyone else has an idea?
Currently my code uses “NSFont_coveredCharacterSet” to get the characters covered by the font, NSCharacterSet_longCharacterIsMember to check if that character set contains the code points I’m checking for.
That all works a treat, except for a series of Fonts called “BM Dohyeon”, “BM Hanna 11yrs Old”, “BM Hanna Air”, “BM Hanna Pro”, “BM Jua”, “BM Kirang Haerang” and “BM Yeonsung”
So I’ve make it work by using a an image, rendering the character into that image and checking that I actually have something drawn.
I’ve put together a class to allow you to detect the scripts available for a given font. I’m put it up on GitHub here
I’ve put an MIT license on it so you can do what ever you want with it.
To use it import it into your application and then call it as follows:
Var cSample As String = ""
Var oFontScripts As New FontScripts( g.FontName )
Var Scripts() As String = oFontScripts.KnownScripts
For Each Script As String In Scripts
If oFontScripts.SupportsScript( Script ) Then
cSample = cSample + Script
End if
Next
cSample = cSample + oFontScripts.Symbols // Returns the first two symbols it finds
Obviously you can add a delimiter between the Scripts you find (such as a space) or you can break the string into multiple lines etc. If anyone knows of a faster way of detecting a completely white or completely transparent square then I would be happy to update the code.
Currently Macintosh only. If anyone with Windows or Linux knowledge would like to extend it for those platforms I’m happy to be involved.
Currently supports 156 different scripts. If anyone would like to suggest a different character for a given script, especially if it is one that Apple is using and I’m not that would be good.