The Languaje Reference states: If you need to write the file using a particular encoding, use the ConvertEncoding function to first convert the encoding of the text to the desired encoding before passing the text to the Write or WriteLine methods.
BUT if you need this documented functionality to save a file with a “particular encoding”, lets say WindowsANSI, copy and paste the example to test it, just changing the desired encoding:
Var documents As FolderItem = SpecialFolder.Documents
If documents <> Nil Then
Var file As FolderItem = Documents.Child("Sample.txt")
If file <> Nil Then
Try
// TextOutputStream.Create raises an IOException if it can't open the file for some reason.
Var output As TextOutputStream = TextOutputStream.Create(file)
output.Write(ConvertEncoding(TextField1.Value, Encodings.WindowsANSI)) '<- The particular encoding (only change)
output.Close
Catch e As IOException
// handle
End Try
End If
End If
Your file is created and SURPRISE it is not a WindowsANSI file, it is a UTF8 File WTF?
The Write method of the TextOutputStream will convert the text to UTF8 IGNORING the enconding of the string passed.
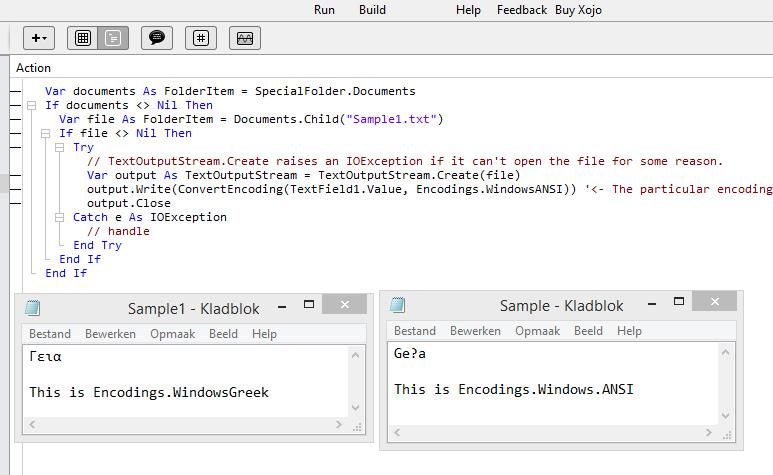
If you want to save a file with a particular encoding that is not UTF8, you have to use a workaround, fortunatelly I found it already on the forum in a post of 2016: How to create a file of ANSI type - #2 by Jeff_Tullin
Use a BinaryStream to write a text file 
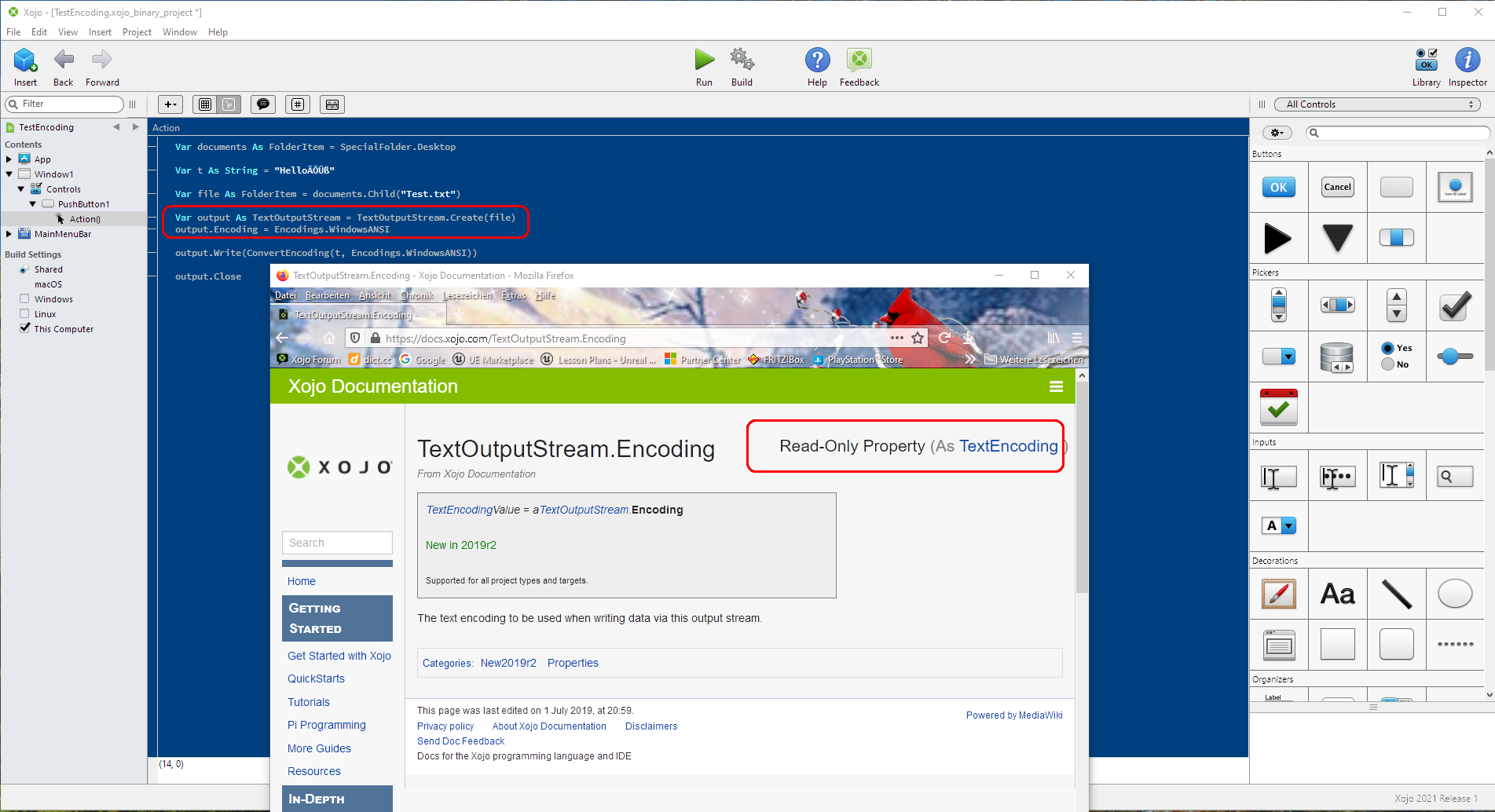
A little more reading an turns out that Xojo unintentionally kind of “fix” this bug (More likely added another workaround) by adding the new Encoding property to the TextOutputStream in 2019r2+, now xojo can just say that is a documentation bug and change the examples in TextOutputStream.
Just the usual mess: ancient bugs, feedback cases ignored, incorrect documentation, half baked features, silent behavior changes…
Workarounds:
if you need a file with a particular encoding use a BinaryStream to save text,
if you have 2019r2+, maybe the new Encoding property will work fine 
 Var documents As FolderItem = SpecialFolder.Documents
Var documents As FolderItem = SpecialFolder.Documents