I’m working on an app for internal use that needs to parse a subset of emails in a mailbox, exported from Apple Mail using the Save As command. (Select multiple emails from the mailbox and choose Save As…) – this saves the emails to a plain text file, which is what I’m parsing.
So two things…
FIRST:
(for the purpose of this screenshot, I’ve extracted two emails and changed the names, but otherwise left things intact):
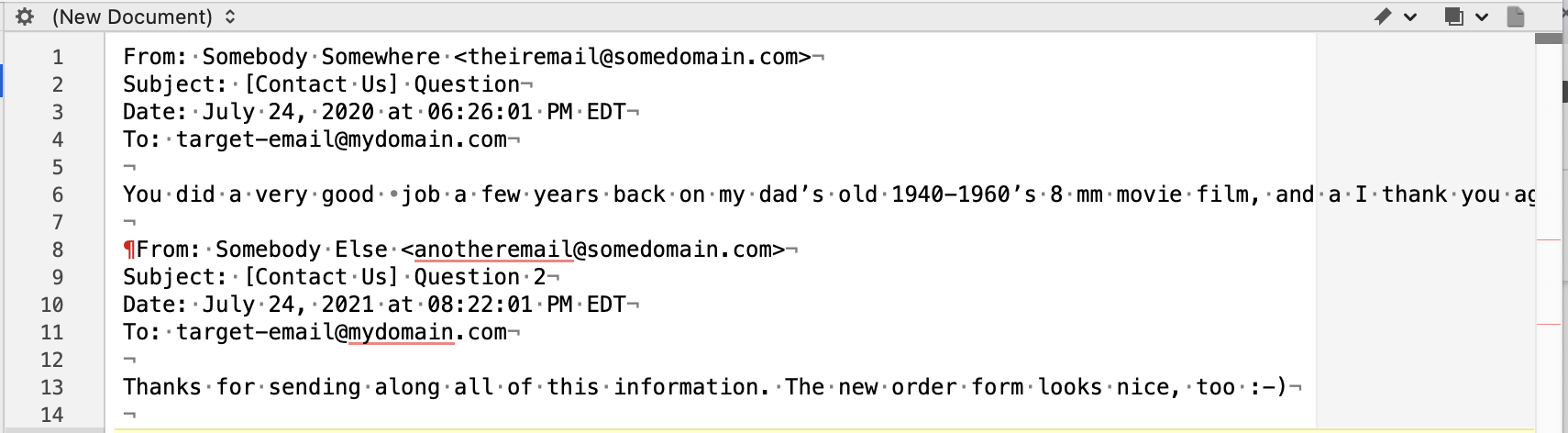
The first email, at the beginning of the document, starts with the F in From: as the first character. Subsequent From lines have a paragraph character at the beginning of the line, like you see in the second email – but I’m only seeing this on the From line, no others. I think that’s causing problems and I’d like to filter it out - but how? What character is that? BBEdit show it as “\f” but how would I remove that in Xojo?
SECOND ISSUE:
The other thing that’s weird is that my code splits the text (which is in a string called mailboxRaw, generated from a textinputstream) on EndOfLine, but that doesn’t seem to be working, at least not all the time:
var mailboxArray() as string
var fromAddress as string
mailboxArray = mailboxRaw.split(EndOfLine)
For i As Integer = mailboxArray.FirstIndex To mailboxArray.LastIndex
// Parse lines starting with "From: ".
If mailboxArray(i).Left(6) = "From: " Then
fromAddress = mailboxArray(i)
parseFromLines(fromAddress)
end If
Next
Sometimes it works fine and the only thing in fromAddress is the From: line, but sometimes the linebreak at the end of the From: line is ignored, and when i look at it in the debugger, it looks like this:
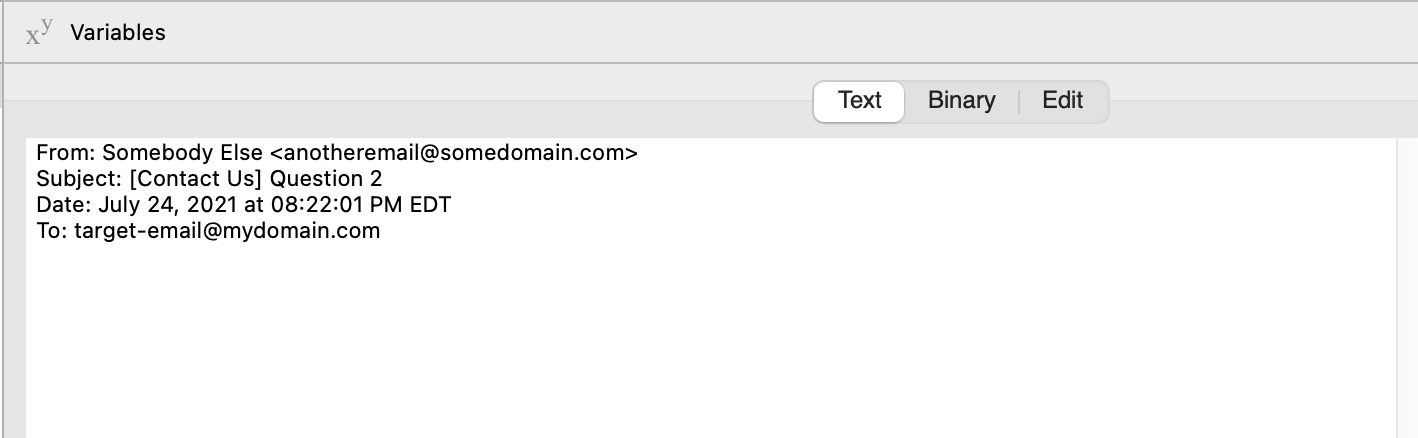
In the actual email, there’s a blank line after the To: line, before the message body starts. But there are clearly line breaks between the From, Subject, Date and To lines, which you can see here (and you can also see them in the BBEdit screen shots with Show Invisibles turned on).
mailboxArray = mailboxRaw.split(EndOfLine)
It seems it’s not splitting on the end of line until it hits two EOLs in a row (in the line after the To: line, which seems to be the pattern in the cases where it does what you see in this debugger screenshot) and is combining these four lines into one.