Please make a fb report, we should absolutely not get slowdowns in API 2.
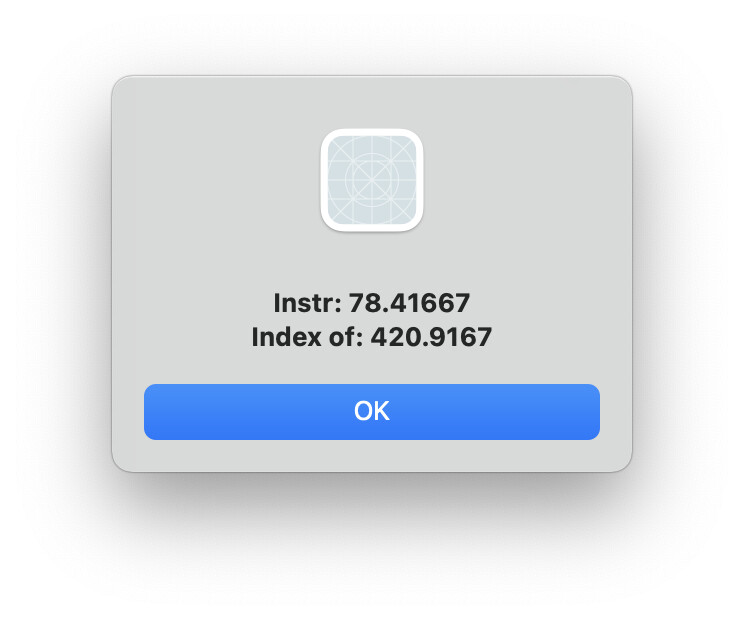
Do you have a Feedback case number? I did a super simple test with a very short string. Even there IndexOf was 3 times slower.
1 Like
No, I have not created a FB of this. I just noticed this today when porting my code to API2 (and that I already reverted back to API1 
In fact, I do not care if the new API2 is slower, as long they keep API1 (which is obviously in some/many parts faster).
How do you expect the Xojo guys to fix problems? With telepathy?
<https://xojo.com/issue/66756>:
IndexOf much slower than Instr
4 Likes
I know and you are right. Thank you for creating the FB
Maybe I should add a FB about if() and if…then too but I don’t think they will/can improve this. Probably a feature instead of a bug.
2 Likes
I got you an answer in my blog: If vs If in Xojo
4 Likes
Thank you for this.
I want to add when you do this in Swift, it doesn’t matter integer or string, if() is always a lot faster compared to if…then
So imo it is not good implemented (at compiler level?) in Xojo.
1 Like
@Christian_Schmitz had a nice blog article about speeding up string processing. Well worth reading.
2 Likes
I know and learned a lot of it too.
1 Like
what bout instrb v.s.the API 2.0 equivalent?
I believe that Swift defaults to immutables and its just a question of assigning a pointer, but Xojo defaults to mutables and needs “copies” of values, and making that takes clock ticks.
3 Likes
That was one of the hardest things to get my head around when learning Objective-C, immutable objects. I hated it.
2 Likes
![]() I know that Xojo users would too.
I know that Xojo users would too.
But immutables are today the State of the Art of value declarations and languages have things like let and var to differentiate them instead of just var or Dim or whatever in the past. The current law is, constants and immutables everywhere, mutables where is needed.
1 Like
UTF8 scans done right have higher cost than fixed bytes standards like ISO8859-1, maybe ParseDate were using a “relaxed scan” (assuming a set of one byte chars) right in C and now they use a more complete (correct but heavier) UTF8 lib for the job do calls for this lib adding an overhead. If I do remember correctly, many string handlings were changed to make a better/proper use of current UTF8 standards.
What is the benefit? I read a dictionary, make it mutable, edit it and copy it back to the original dictionary. I had to do that with CFDictionaryMBS in the last days for a LaunchAgent.
Speed and Size and less prone to dev errors and NOEs.
If you declare (depends on your compiler) n identical constant values in your code, in memory the compiler could solve them all as just one value in memory. If immutables all the processing may be pointer based many times not needing copies and not null once you guaranteed the initialization. The compiler can always favor speed and size where mutables can’t.
1 Like
This is excellent sleuthing. Thank you Christian Schmitz.
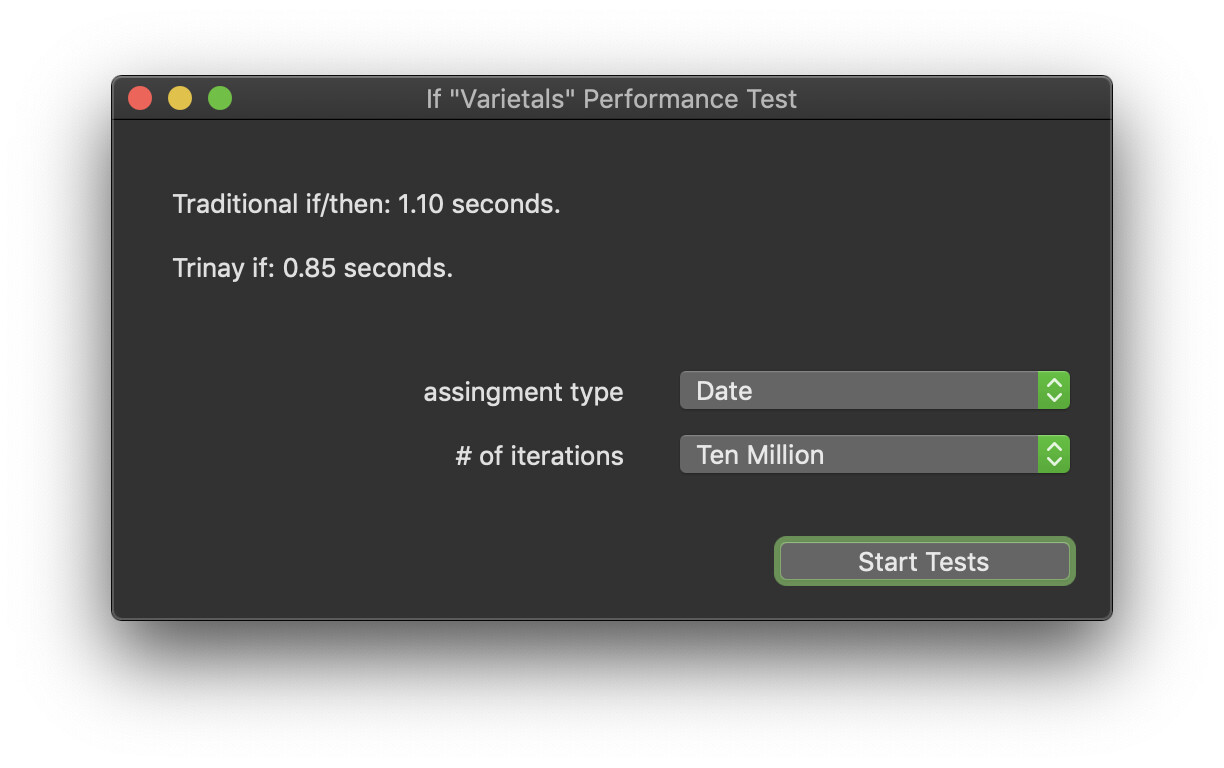
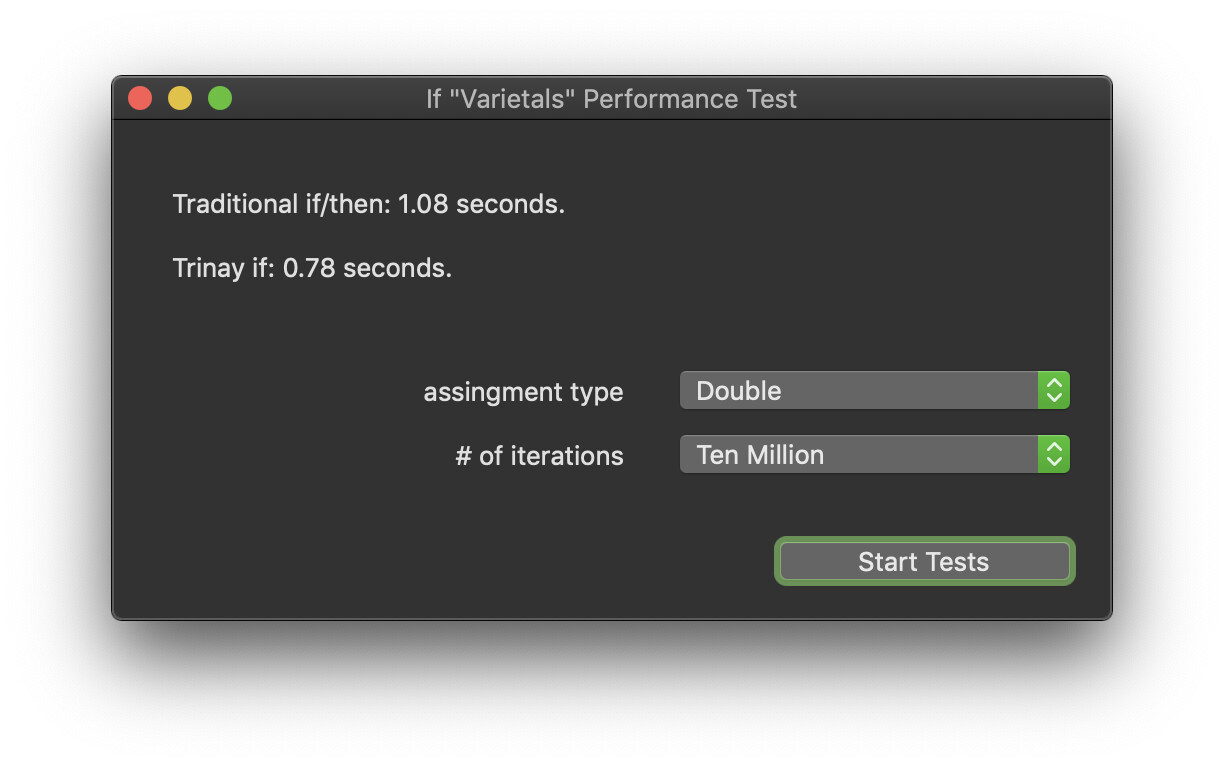
I did a little bit more testing this AM, using some additional types (“Date”, “Double”, “DateTime”).
For what it’s worth… In my testing, the only conditions where the inline version of “If” seems to be slower is when a “String” is involved. (matching Christian’s findings)
Assigning a “String” to a “Variant” was exceptionally slow, but assigning an “Integer” to a “Variant” was still quicker using the inline version of “If”
For every other type I tested, the inline version of “If” was quicker.
Sample Project: Dropbox - sample_project.xojo_binary_project.zip - Simplify your life
Some examples:

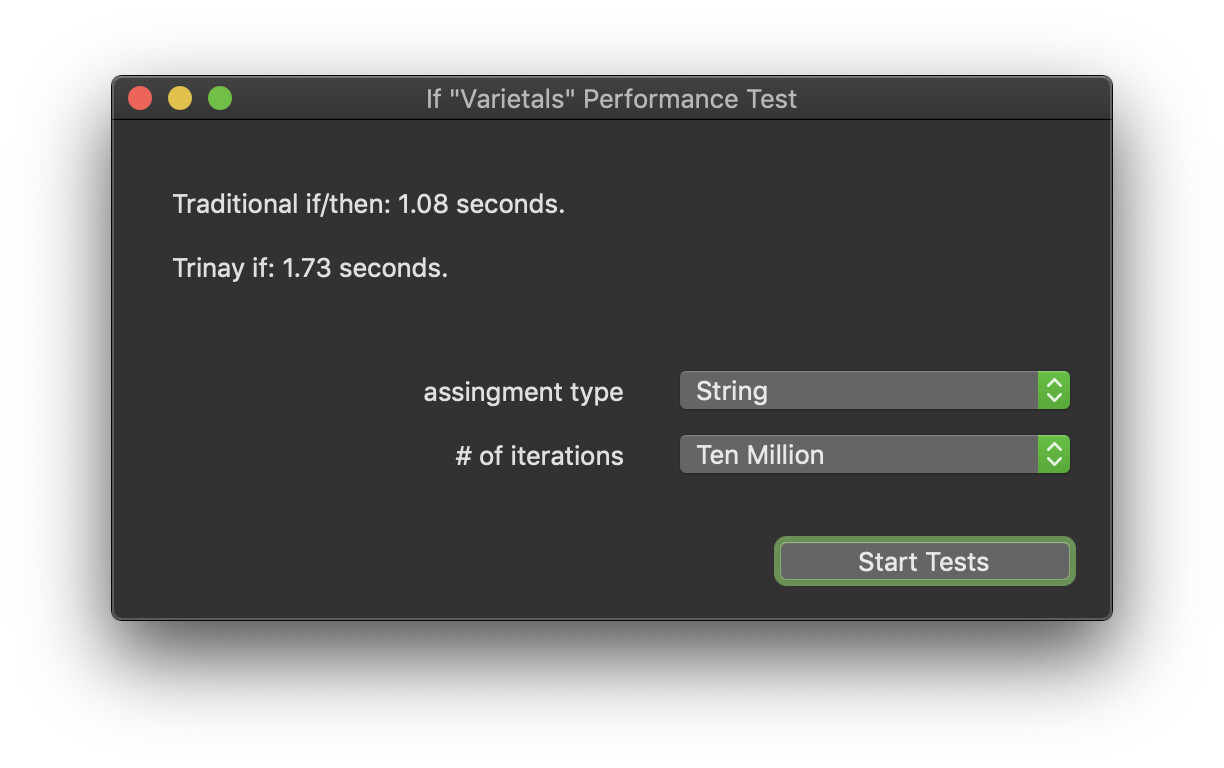
(string is slower)
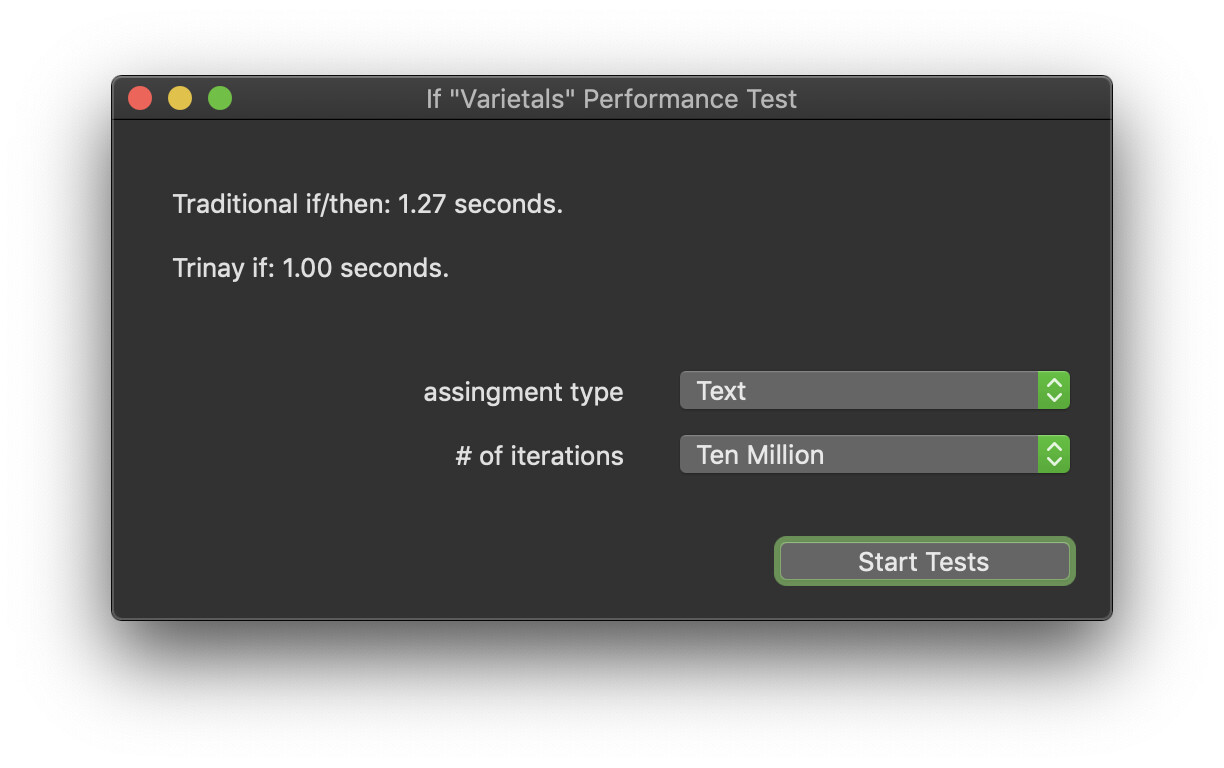
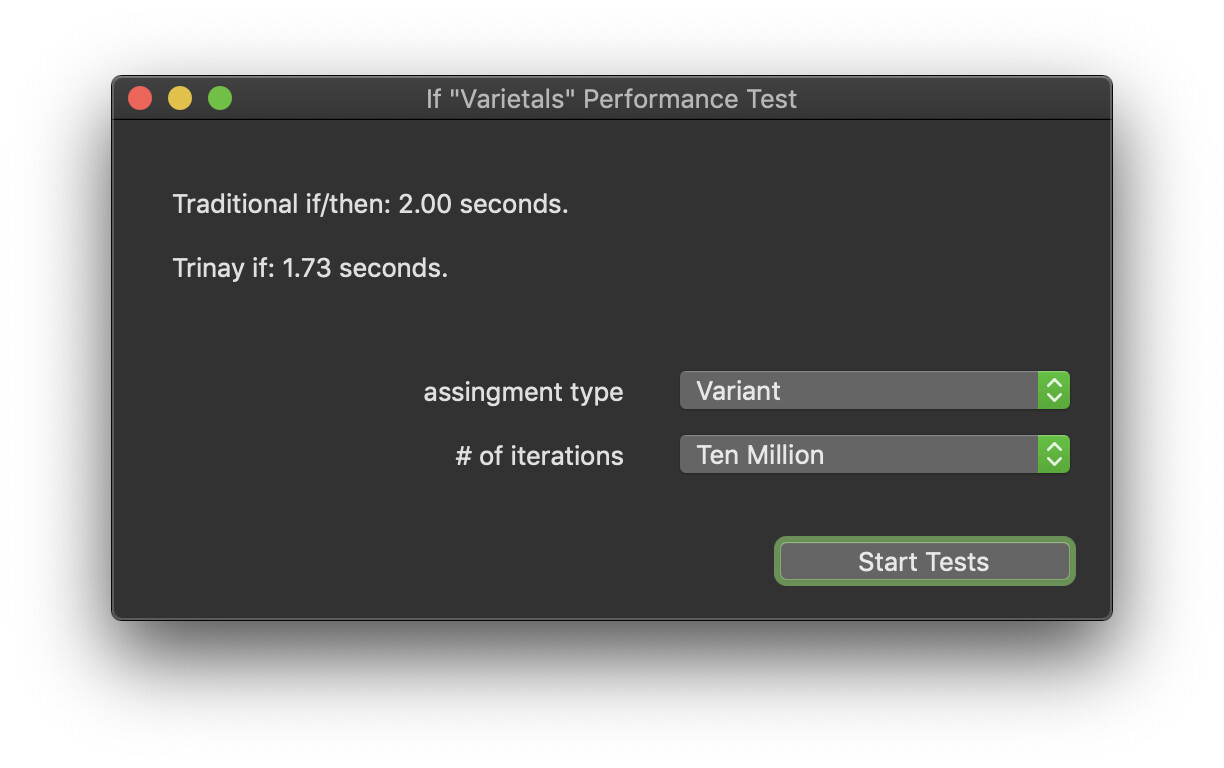
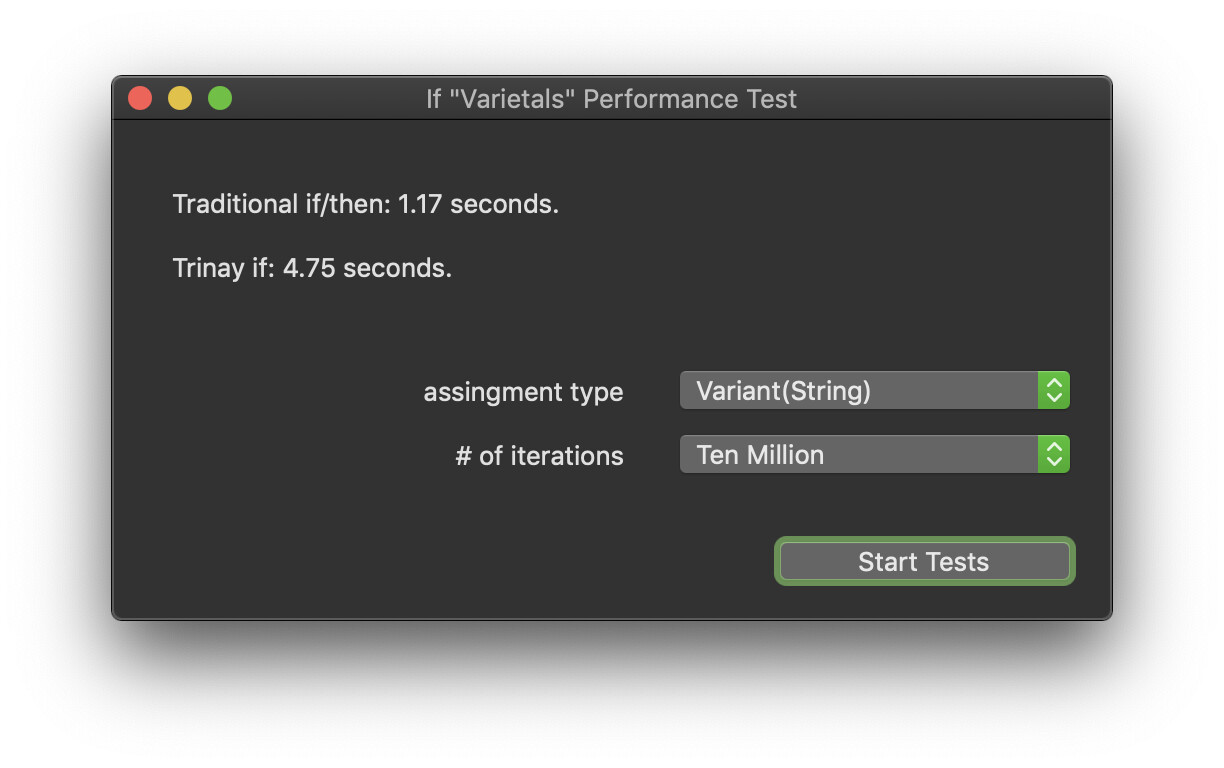
(assigning a string to a variant is MUCH slower)
2 Likes
Be aware there also may be big platform differences, e.g. <https://xojo.com/issue/65723>
- String.Characters Iterator is 1000x slower on Windows than macOS
2 Likes