Read the table one more time; it is 1011, not Chr(11)…
Be careful with Internet ASCII tables… some of them are correct from Ctrl-0 to 127, and continue until 255… (128 to 255 are not ASCII code; they are something else).
Read the table one more time; it is 1011, not Chr(11)…
Be careful with Internet ASCII tables… some of them are correct from Ctrl-0 to 127, and continue until 255… (128 to 255 are not ASCII code; they are something else).
Vertical tab is definitely Chr(11). It shows up as ASCII 11 in a hex editor, within Notepad3 it displays as “VT”, and Wikipedia confirms it too.
1011 is 11 in binary, which might be what you’re seeing.
Agreed with needing to be careful with charts though, for that very reason! Legacy 7-bit ASCII is what limits the values up to 127 since they didn’t set the high bit of the byte. Values of 128-255 require that last bit.
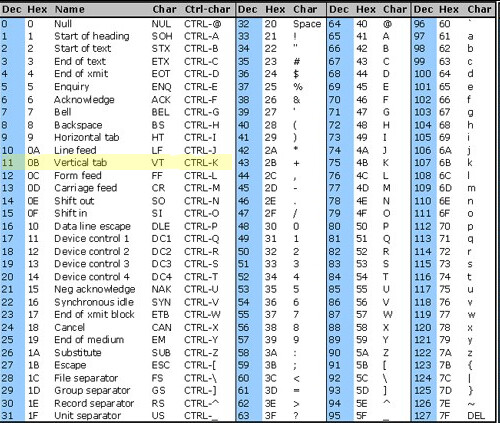
7-bit ASCII is not what is the legacy, as it is part of UTF-8. What is legacy is all those so-called “code pages” which try and use values 128 to 255. They should all go into the Trash.
Possibly worth investigating and reporting an issue.
I’m now told:
Keyboards don’t send ASCII, they send keycodes. There can be a certain degree of overlap, but in general terms you need a translation from the keycodes to the character(s) the key is expected to generate. This mapping varies depending on the keyboard layout (QWERTY v AZERTY, modifier keys, dead keys, mapping ¬`|@"~# on different layouts like US v UK, etc).
It’s quite possible that there’s a keyboard that sends the keycode 11, but that shouldn’t be taken to be ASCII 11.
Why are-you talking about key codes ? It adds nothing to resolve the case.
For Information:
KeyCode is the hardware value of a key on a keyboard that is sent to the OS. The OS translate that, using the default (or a user choosen) layout, to a character.
So, to read a text file, forget that you read something abour KeyCode.
May it be your user is writing within MS Word? Because Word is using Chr(11) when the user is doing a manual line break (Shift + Enter)?
As I said. There are line breaks (&u0d+&u0a, &u0d or &u0a) and soft line breaks (that some softwares uses VT (&u0b) to mark such place. So, not an issue, just handle them as you intend.
So, what are soft like breaks? Are places where you want to move the text continuation to the next line BUT not starting a new paragraph. Let’s use bullets trying to explain it:
Some people will opt to replace &u0b (Chr(11)) by a line break as &u0a, and in some contexts they may opt to replace them by a space as " ", and the results will be:
This is one line with a soft line break
and this is the continuation of it.
or
This is one line with a soft line break and this is the continuation of it.
While it’s true keyboards send key codes, what one gets in a KeyDown event and in the resulting text field are really character codes (not ASCII codes, since for instance, “é” isn’t an ASCII character). So what’s relevant here is indeed the character code generated by the OS [for the key code sent by the keyboard].
Hmmm. The Keyboard module allows one to detect if a particular key or modifier is being pressed at this instant, but it doesn’t look like one can ask it which key is being pressed.