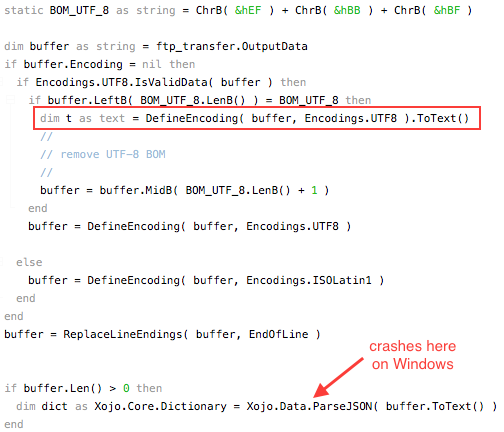
I receive data via FTP, a string with a NIL encoding. The data is in JSON format that I convert to a Xojo.Core.Dictionary.
This is the data I receive. As you can see, it has the BOM for UTF-8.
This is my code:
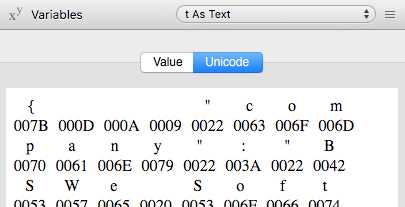
First please look a the variable “t”; it’s converted to text. On the Mac it’s OK:
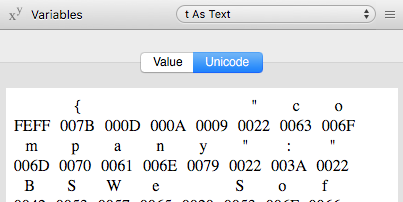
On Windows, the text has now the BOM for UTF-16:
I don’t know if that’s a problem so far but with the UTF-16 BOM on Windows Xojo.Data.ParseJSON() throws an InvalidJSONException if do not remove the UTF-8 BOM manually.
Markus, I already have a string (ftp_transfer.OutputData) that’s content is exactly the same on Mac and Windows. The problem is, that after defining Encodings.UTF8 the conversion to text adds the UTF-16 BOM to the text what’s not the case on Mac.
a) It’s an exception and not a crash.
b) Don’t use the new framework (not really kidding). Hey, the conversion to the new framework is supposed to be easy and simple.
c) Isn’t defineEncoding old framework?
d) Do a bug report.
Going based on what you have presented you have a couple options:
Use the classic framework’s JSONItem class to parse the JSON. This would be a significant change as JSONItem is a completely different API than a Xojo.Core.Dictionary
Switch to Xojo.Net.TCPSocket for your FTP code so you do not have to make the Text conversion. This is assuming you wrote a FTP client. If you are using a plugin then this may not be possible.
My intuition tells me there has to be something else going on than the Text conversion itself. I use String -> Text conversion for JSON extensively in my Rapid Services product and have never encountered an issue like this. In that product I convert web controls String properties to Text and into JSON and back extensively.
I have a sneaky suspicion that the ReplaceLineEndings() method may not be doing what you expect depending on host platform. I would start there and verify it is working correctly.
Again: The issue is here, that the from-string-to-text conversion behaves different on the two platforms (not tested on other platforms so far).
Philipp, indeed I the data comes from a plugin. The data I receive is send from a text file to me that is created on Windows and saved as UTF-8, so it has the BOM &hFEFF. A workaround is, to remove the BOM before working with the data (you see it in the line below the comment “remove UTF-8 BOM”).
If Xojo are using the operating system text APIs under the hood then it is probably a difference in how they operate rather than a Xojo issue.
Personally, I would always remove any type of BOM before assigning an encoding to some data. As far as i’m aware the purpose of a BOM is only to say that the following stream of data is Unicode text. If you leave it in the data when you assign the encoding then you are prefixing your string with some type of Unicode code point.
Kevin, you mean it’s not a bug? OK, I can agree. But the behaviour is different on platforms and that should not be. Inconsistency prevents code to work cross-platform. And there are still too many functions in the new framework that work inconsistent.
And if we care about “beginners”…
The crash, sorry the exception, is not the bug (if it is one). I think ParseJSON() does the same (right), if the text has a BOM like on Windows. But it has no BOM on macOS, because ToText() converts it away. In my eyes this difference is the bug.
The question is if really the same string is coming on on both Windows and macOS. Are they the same prior to the encoding line? And why not split the two statements to too lines:
Dim buffer As String = ftp_transfer.OutputData
BREAK // Check here if the strings are identical
Dim s As String = buffer.DefineEncoding(Encodings.UTF8)
BREAK // Check here if the strings are identical
Dim t As Text = s.ToText
BREAK // Check here if the strings are identical
Eli, believe me, the data is exactly the same on both platforms; the FTP server is the same and sends the same bytes in the same order no matter who the receiver is.
“Believe me” I have seen this before my post in the debugger! Otherwise I would not have implemented the workaround to remove the BOM. See my first screenshot, it shows the same received data on macOS and Windows.
DefineEncoding does the same on macOS and Windows; it does not change the bytes.
The issue is definitely ToText() because it works different. If you don’t believe me, try it yourself.