With LiveText, I get a table with an index in the first column, then a title in the second column who is UPPERCASE…
I used TitleCase (these are US English Comics titles) on that two columns, and the first character of the title, after \Tab (Column Separator) is set to LowerCase (not TitleCase).
Same apply with complex words like swamp-man; the m stays LowerCase.
Resulting text after applying TitleCase:
115 tim Makes A Lucky Trip
116 spud Saves Tim’s Life
117 the Strange Cafe Of Capitan Stacey
118 a Jungle Surprise Party
119 the Big Chance
120 The Jungle Stilmen
121 the Jungle Clown
122 a Wild Chase
123 caporal Spud Has Troubles
124 the Unlucky Winner
125 and Odd Race For Life
126 the Jungle Island
127 crisis At Garat
128 the Fifth Seal
129 the Pomo Light
130 naduwa Crater
131 the Naga Hills Mystery
132 the Lagoda Prize
The space after the number (115 to 132) is a Tab character.
At last, before writing this post, I was going to read the rules @ wikipedia and the TitleCase have to be set if both part of the composite word are important like in Man-Beast, or whatever other example (I forget the given examples).
Yes, it is in the original text. It is not on this forum because of the used software…
That is why I noted a second time what is that “space”<;
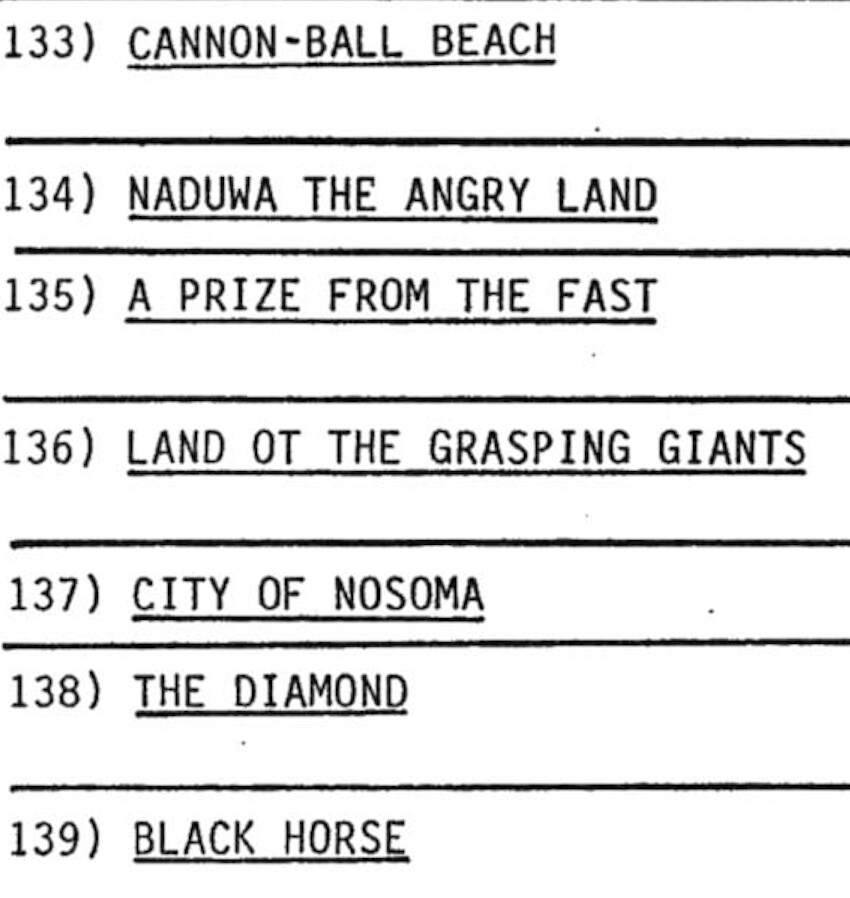
I know it is a Tab character because I set it. If you look at the scanned image, the original text is:
133) CANNON-BALL BEACH
(underlined was lost by LiveText).
I removed ") " and replaced them with a Tab (and so the remaining of the lines, I removed spaces and replaced them with Tabs…).
I may be a bit sleepy, lost my memory, etc. but sometimes I recall what I have done minutes ago (and yesterday, and… - this is a boring process, so I do bits, let time ellapsing, continue, do something else, continue until it is fully done.)
I don’t recall how specific the TitleCase() docs are but on all the systems where I’ve used it, it’s a fairly simplistic implementation and doesn’t assume much about the input text as to language rules, nor reasonably should it IMO. It has no idea if the input text will be English or Bulgarian or whatever. I use it in an engine I’m building to convert all upper case to mixed case as a first step, and I always make sure inputs have no whitespace other than single spaces, no punctuation at all, and then apply various heuristics from there. There are many, MANY exceptions to simple title casing, especially when your inputs are business names and you have to correctly handle weird / edgy branding capitalizations and hyphenations and the like.
Bad news, in my next attempt, I copy the text to TitleCase as “Column” (Option-Drag vertically or so) to get only the text. Then I applied TitleCase: the first letter of each line is set to LowerCase… similar result to what I say above… Strange.
Here’s the wikipedia reference page I read before opening this thread:
I only talked about the rules I found there.
I’m French, and when I want correct French casing in a text, I use LowerCase and change manually when TitleCase is needed (first character of a sentence, Names, acronyms…).
What I have found SO FAR is that TitleCase() dumbly capitalizes the first letter of each “word” in a string, considering a “word” to be anything bounded by either whitespace or beginning or end of the string. So to me TitleCase() is just a way to get that initial conversion done and then I handle exceptions myself through various tables of words, phrases and entire business names about which certain assumptions can be made (e.g., any known business ending is already in the name, etc).
I’m not sure why it’s capitalizing only the first letter for you. The docs specifically state: “Converts all characters in a String to lowercase characters and then converts the first character of each word to uppercase.” Are you sure you’re calling the Xojo framework or something else? Is there some character delimiting the words other than whitespace that TitleCase() recognizes?
I used TitleCase (these are US English Comics titles) on that two columns, and the first character of the title, after \Tab (Column Separator) is set to LowerCase (not TitleCase).
I only complaining about the first character of the first word of every sentences…
But earlier today, I get different results… Same computer, no software update, only the standard reboot, and I get my first word starting with a Capital character !
Yes, the last word is terminated by end of string. Similar to Regex expressions of the form “^Whatever$” In that case the one word Whatever isn’t bound by whitespace, but by start AND end of string.
I haven’t tested this but it may be that TitleCase only recognizes space as a delimiter or at least doesn’t recognize tab characters as whitespace. It sounds like your results vary because the input string isn’t in some known state. My input strings have only a single space character between words. I have a method that collapses all consecutive spaces to single spaces first, and prior to that, all non-ASCII characters and a defined set of punctuation is also removed or replaced. In this fashion the inputs to TitleCase are quite uniform. If for example you are effectively parsing text coming from optical character recognition your processing should assume a certain amount of “noise” in the resulting text. If your input is user-typed, then you should expect a certain amount of inconsistency of a somewhat different nature.
You always want to remove all possible variables that you can each step of the way.
Sorry, I understand nothing about Regex expressions.
I’m trying to understand your example, as it doesn’t sound right to me (but I’m not sure I understand the example )
What I understand you’re saying is: given this sentence “This is a sentence meaning nothing” the result would be “This Is A Sentence Meaning NothinG” (capitalising every start of word + the end of string), which is wrong.
On the other hand, if you’re actually saying that “nothing” is at the end of the string, I’d agree but wouldn’t see your point: “Nothing” would be capitalised like any other word, be it at the end, start or middle of the string.
I am saying the first letter of each and every word would be capitalized, and “word” is defined as a string of non-space characters that ends when a space is encountered. Technically, the first and last “words” are special cases where the start or end of string serves to delimit the start / end of those particular words. For your purposes if the input string has only single spaces in it then it will have a number of words equal to the number of spaces plus one – that would be another way to look at it. But I think I am giving you TMI (Too Much Information). I think the basic problem the OP is having is that there are non-obvious characters embedded in the string that TitleCase() doesn’t recognize as whitespace or word boundaries. My theory is that tabs aren’t considered word delimiters by TitleCase() for example. The solution is to prepare the string to insure it’s in a known state (no whitespace or invisible characters other than actual ASCII spaces – Chr(32) – no consecutive spaces, and depending on what you’re trying to accomplish, possibly some other variations already eliminated. For example ABC Supplies could be “ABC Supplies”, “A.B.C. Supplies”, “A B C Supplies”, even “A-B-C Supplies”, and that’s even ignoring the presence or absence of “business endings” (Inc, LLC, LLP, Ltd, Corp, Co and so forth), mis-spellings, fat-fingered capitalizations that are incorrect, and a host of other things. So depending on what you’re trying to accomplish, TitleCase() might be able to do most of the heavy lifting, or may only play a relatively basic role that needs other logic surrounding it.