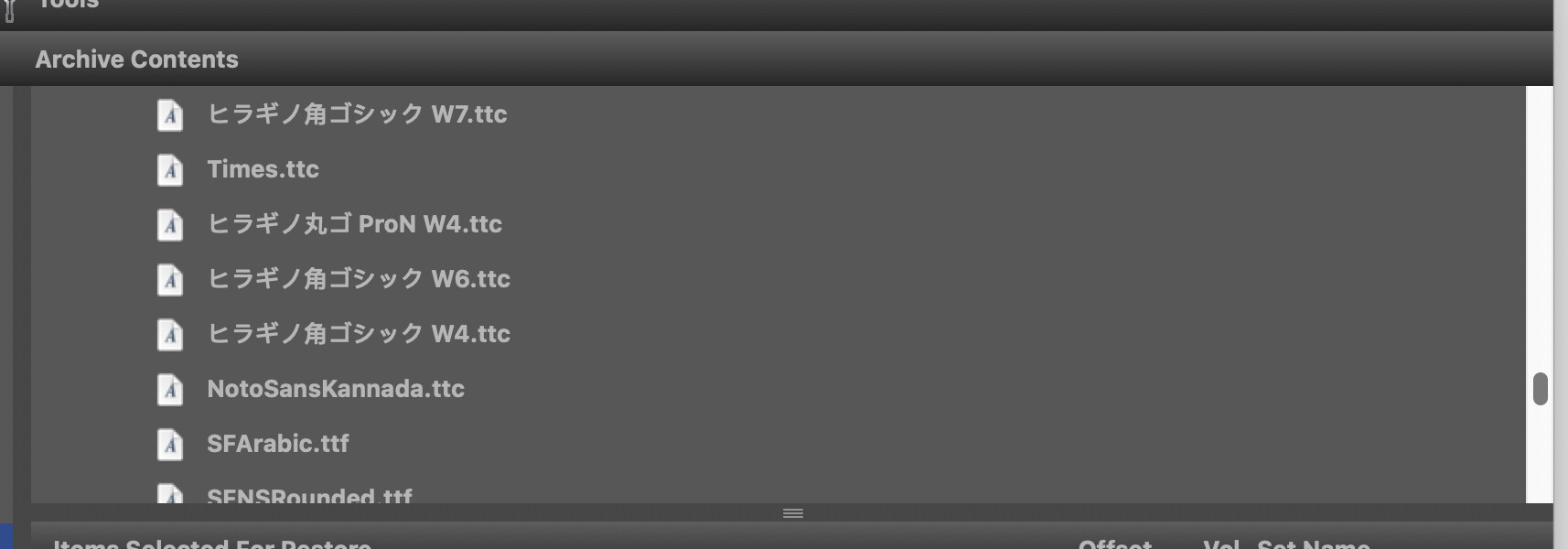
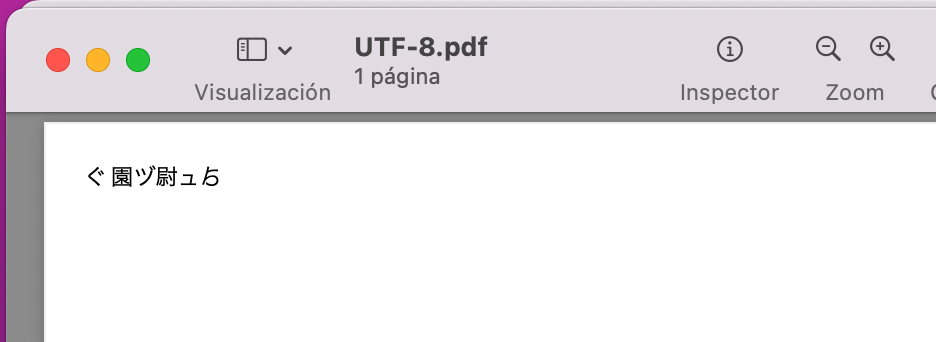
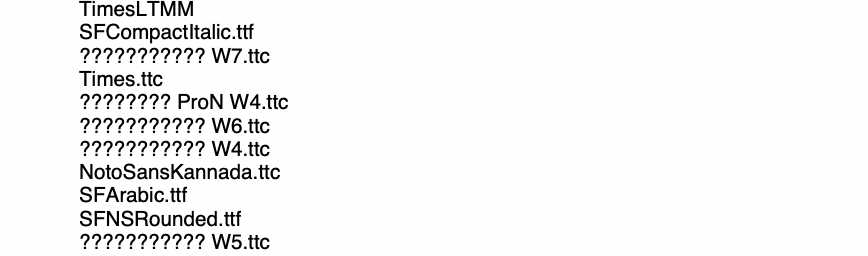Since there is no UTF-8 support yet for PDF creation I tried the suggested solution (text2picture).
I have a strange behaviour in PDF document with 2 pages.
I draw one picture per page and the result is PDF document replays first picture to second page and ignores second picture.
Example (2022R3.2)
Var pDocument As New PDFDocument
pDocument.Creator = “Xojo”
pDocument.Author = “Xojo”
pDocument.Keywords = “Xojo, PDF, Example”
pDocument.Title = “PDF - Page Layout Example”
pDocument.Subject = “PDF - Page Layout Example”
pDocument.Compressed = False
Var G As Graphics=pDocument.Graphics
//MAKE PAGE1
Var p1 As New Picture(g.Width2, g.Height2)
p1.Graphics.FontSize = 22
For i As Integer=1 To 10
p1.Graphics.DrawText(“AAAAAAAAAAA”+Str(i), 10, p1.Graphics.FontAscent*i,300,True)
Next
G.DrawPicture(p1, 20, 20, g.Width, g.Height, 0, 0, p1.Width, p1.Height)
pDocument.Graphics.NextPage
//MAKE PAGE2
Var p2 As New Picture(g.Width2, g.Height2)
p2.Graphics.FontSize = 22
For i As Integer=1 To 10
p2.Graphics.DrawText("BBBBBBBBBBB "+Str(i), 0, p2.Graphics.FontAscent*i)
Next
G.DrawPicture(p2, 20, 20, g.Width, g.Height, 0, 0, p2.Width, p2.Height)
Var f As FolderItem = SpecialFolder.Desktop.Child(“output.pdf”)
Try
pDocument.Save(f)
f.Open
Catch e As IOException
MessageBox(e.Message)
End Try