Both @Norman Palardy and @Eli Ott have been VERY helpful, and I am almost there.
My first mistake was changing the size of a C-String on Windows and Mac, in which they are both the same length.
H
e
l
l
o
.W
o
r
l
d
. //WString Mac (48 bytes)
H.e.l.l.o
W.o.r.l.d
//WString Windows (24 bytes)
Hello.World. //CString Windows and Mac (12 bytes)
Hello.World //String Windows and Mac (11 bytes)
Eli, thanks for explaining the nil encoding after the \0 end marker on Mac, this makes sense now. The good news is that using the UTF8 encoding allows the output to look good on Mac, and unfortunately, the WString on Windows is now not recognizing the EndOfLine.
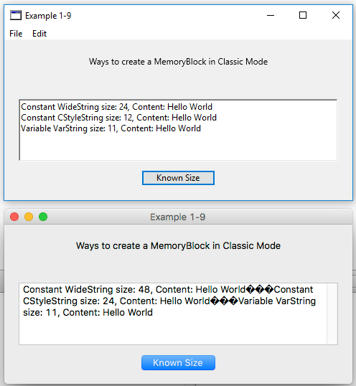
Windows Version 1.1
Constant WideString size: 24, Content: HConstant CStyleString size: 12, Content: Hello World
Variable VarString size: 11, Content: Hello World
EndofLine after the WString does not seem to be recognized on Windows.
Mac Version 1.1
Constant WideString size: 48, Content: Hello World
Constant CStyleString size: 12, Content: Hello World
Variable VarString size: 11, Content: Hello World
Here is the code for this example:
[code]Version 1.1
Sub Action() Handles Action
//WString
#If TargetWindows //Windows OS
Dim WideString as New MemoryBlock(24)
#Else //Mac and Linux
Dim WideString as New MemoryBlock(48)
#EndIf
Dim s as String
WideString.WString(0) = “Hello World”
s = WideString.WString(0).DefineEncoding(Encodings.UTF8)
TextArea1.Text = "Constant WideString size: " + WideString.Size.ToText + ", Content: " + s + EndOfLine
//Cstring
//Windows OS and Mac
Dim CStyleString as New MemoryBlock(12)
CStyleString.CString(0) = “Hello World”
s = CStyleString.CString(0).DefineEncoding(Encodings.UTF8)
TextArea1.Text = TextArea1.Text + "Constant CStyleString size: " + CStyleString.Size.ToText + ", Content: " + s + EndOfLine
//String
Dim VarString as MemoryBlock
VarString = “Hello World”
s = s.DefineEncoding(Encodings.UTF8)
TextArea1.Text = TextArea1.Text + "Variable VarString size: " + VarString.Size.ToText + ", Content: " + s
End Sub
[/code]
It looks like the DefineEncoding UTF8 command on Windows is causing the EndofLine to not be recognized. When encoding for Windows is removed, then the EndOfLine formatting seems to be correct and the following code runs as expected on both OS’s:
[code]Version 1.2
Sub Action() Handles Action
//WString
#If TargetWindows //Windows OS
Dim WideString as New MemoryBlock(24)
#Else //Mac and Linux
Dim WideString as New MemoryBlock(48)
#EndIf
Dim s as String
WideString.WString(0) = “Hello World”
s = WideString.WString(0) //.DefineEncoding(Encodings.UTF8) <-commented out
TextArea1.Text = "Constant WideString size: " + WideString.Size.ToText + ", Content: " + s + EndOfLine
//Cstring
//Windows OS and Mac
Dim CStyleString as New MemoryBlock(12)
CStyleString.CString(0) = “Hello World”
s = CStyleString.CString(0).DefineEncoding(Encodings.UTF8)
TextArea1.Text = TextArea1.Text + "Constant CStyleString size: " + CStyleString.Size.ToText + ", Content: " + s + EndOfLine
//String
Dim VarString as MemoryBlock
VarString = “Hello World”
s = s.DefineEncoding(Encodings.UTF8)
TextArea1.Text = TextArea1.Text + "Variable VarString size: " + VarString.Size.ToText + ", Content: " + s
End Sub
[/code]
Mac and Windows Version 1.2
Constant WideString size: 48/24, Content: Hello World //(48 Mac/24 Win)
Constant CStyleString size: 12, Content: Hello World
Variable VarString size: 11, Content: Hello World
EndofLine encoding is an issue with Mac as the two of you mentioned.
Just curious as to why encoding to UTF8 on WString with Windows causes the EndOfLine command to be ignored? Is this a similar situation with Nil and Null differences?
Edit: Added bytes for both Mac and Windows in Version 1.2 screen output